小红书笔记与评论爬虫、抖音视频与评论爬虫、快手视频与评论爬虫、B站视频与评论爬虫、微博帖子与评论爬虫、百度贴吧帖子与评论爬虫、知乎问答文章与评论爬虫
💡 应用场景
MediaCrawler最适合需要从多个自媒体平台批量、自动化采集公开内容(帖子、视频、评论)并进行数据分析的场景,尤其适用于竞品分析、舆情监控和用户研究。
竞品内容监控
问题:需要持续追踪竞品在小红书、抖音等平台的最新笔记和视频,但手动收集效率低且容易遗漏。
方案:使用MediaCrawler的关键词搜索功能,定时爬取指定关键词的内容和评论,自动汇总数据。
示例:运营人员设置关键词'护肤品测评',每天自动抓取小红书和抖音的最新笔记及评论,分析用户反馈趋势。
创作者数据分析
问题:想分析某个头部博主的内容策略和粉丝互动情况,但手动翻页收集数据费时费力。
方案:通过指定创作者主页功能,一键爬取该博主的所有帖子、视频及评论数据,用于内容分析和粉丝画像。
示例:市场分析师爬取某美妆博主在小红书和B站的所有笔记及评论,统计点赞、回复量,评估其影响力和内容偏好。
舆情监控与评论分析
问题:需要快速了解某个热点事件在多个平台上的舆论风向,但手动收集评论并做词云分析太繁琐。
方案:利用项目内置的评论爬取和词云生成功能,输入事件相关帖子ID,自动抓取全量评论并生成可视化词云图。
示例:公关团队针对某品牌负面新闻,爬取微博和知乎相关帖子的全部评论,生成词云图快速识别核心争议点。
用户反馈收集与产品迭代
问题:产品经理需要从贴吧、知乎等平台收集用户对某款App的真实反馈,但分散在不同帖子中难以整理。
方案:使用关键词搜索和指定帖子ID爬取功能,批量抓取相关讨论帖的评论,导出结构化数据用于需求分析。
示例:产品经理搜索'某App 体验',爬取百度贴吧和知乎的帖子及评论,整理出用户最常抱怨的功能点,指导下一版本优化。
📊 项目信息
- 语言
- Python
- Stars
- ⭐ 53,341
- Forks
- 10,974
- 今日新增
- +673
- 排名
- #13
- 收录
- 总榜
- 趋势日期
- 2026年6月26日
- 最后推送
- 2026/6/18
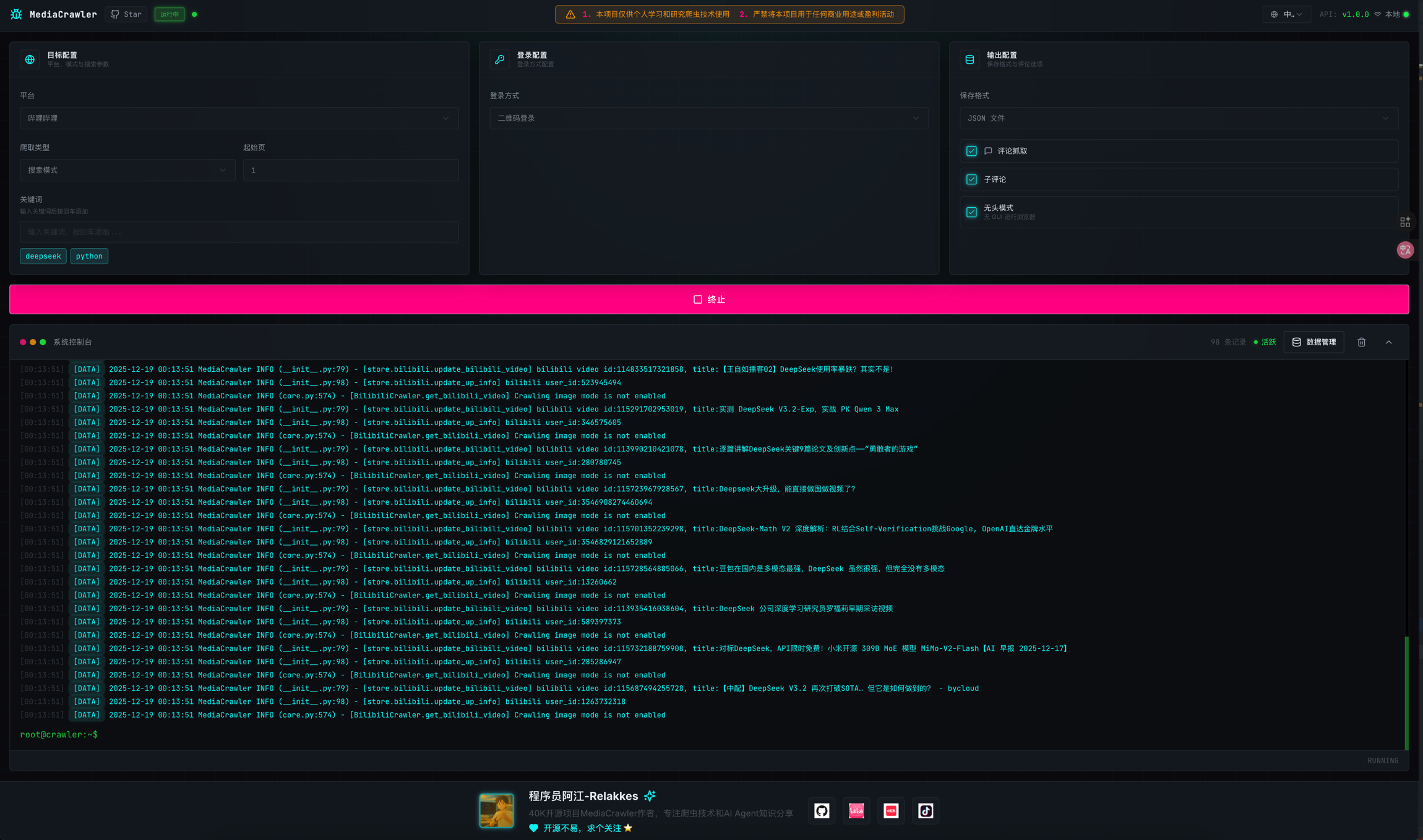
📸 截图