面向AI就绪数据的PDF解析器。
💡 应用场景
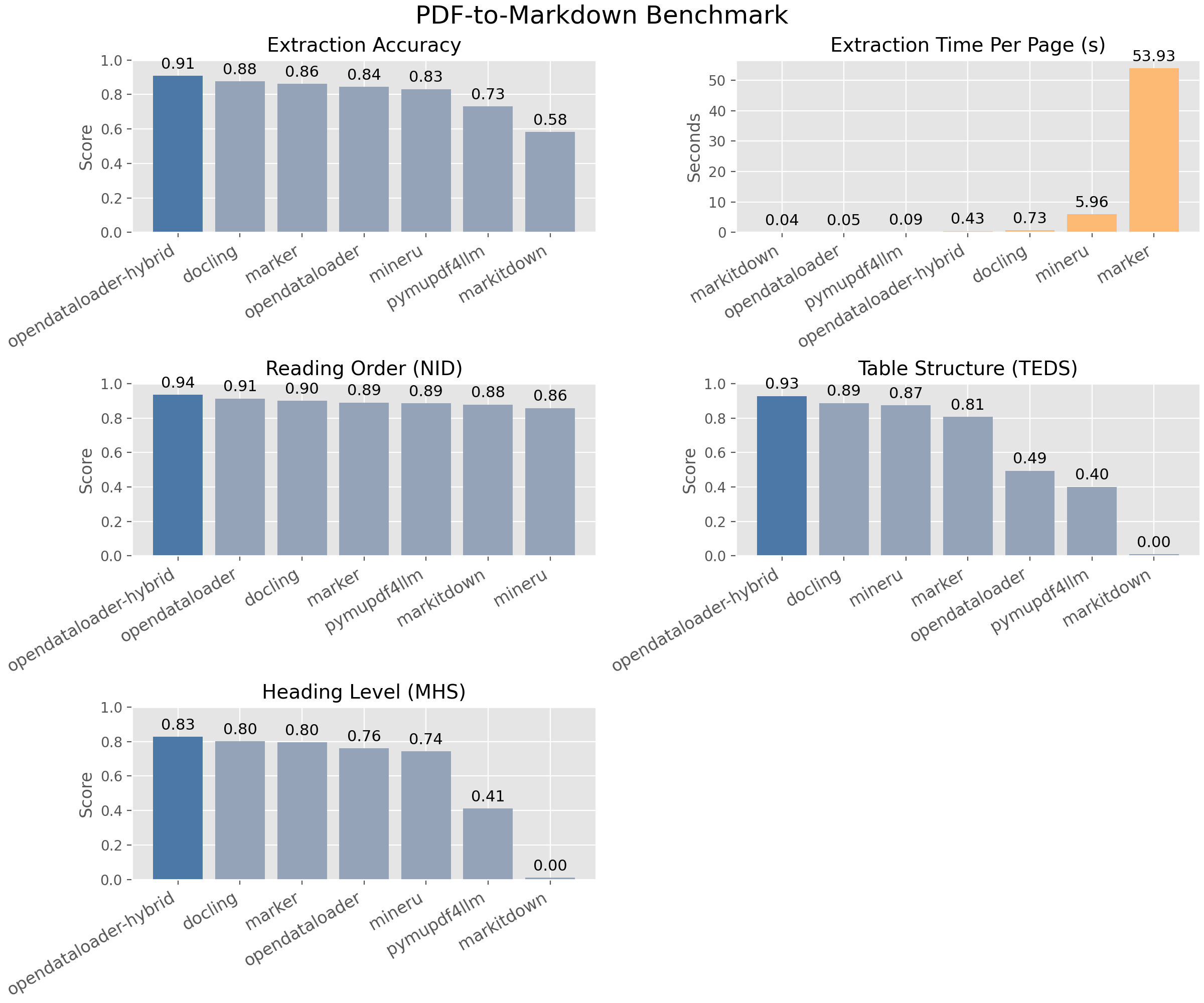
这是一个面向AI数据提取和PDF无障碍自动化的高性能解析器,特别适合需要高精度解析复杂PDF结构(如表格、公式)并保留坐标信息用于RAG溯源,或批量生成无障碍PDF的场景。
RAG文档预处理
问题:开发者需要将PDF文档转换为结构化文本用于RAG系统,但传统解析器会丢失表格、公式等复杂结构,且难以精确定位原文位置进行引用。
方案:使用该解析器将PDF转换为带边界框坐标的JSON或结构化Markdown,保留表格、公式等语义信息,便于后续分块和精确溯源。
示例:构建企业知识库时,将产品手册、技术白皮书等PDF解析为带坐标的JSON,确保RAG回答能准确引用原文的特定段落或表格。
扫描文档数字化
问题:开发者需要处理扫描版PDF或图像质量较差的文档,传统OCR工具识别率低且无法理解文档结构(如多栏排版)。
方案:启用项目的混合模式(内置80+语言OCR),结合布局分析引擎,能准确识别扫描文档的文字、表格,并还原正确的阅读顺序。
示例:数字化档案馆的历史扫描文档(如旧报纸、报告),提取结构化文本和表格数据,用于后续检索或分析。
PDF无障碍自动化
问题:企业需批量生成符合无障碍法规(如PDF/UA)的PDF文档,但手动标记成本高昂(每份50-200美元),且缺乏开源解决方案。
方案:使用项目的自动标记功能(2026年Q2开源),将未标记PDF转换为带标签PDF(Tagged PDF),为生成合规PDF/UA文档奠定基础。
示例:政府机构或教育平台需要将大量公开报告、教学材料转换为无障碍PDF,以满足法规要求并服务视障用户。
学术论文解析
问题:解析学术PDF时,其中的多栏布局、复杂表格、数学公式和图表描述难以被传统解析器准确提取。
方案:利用混合模式(AI辅助)处理复杂页面,能准确提取多栏文本、无边框表格、LaTeX公式,并为图表生成AI描述。
示例:构建学术搜索引擎或文献分析工具时,批量解析arXiv论文,提取完整的文本、公式和表格数据用于索引或元分析。
📊 项目信息
- 语言
- Java
- Stars
- ⭐ 21,790
- Forks
- 2,037
- 今日新增
- +87
- 排名
- #1
- 收录
- 语言榜
- 趋势日期
- 2026年5月29日
- 最后推送
- 2026/5/29
🏷️ 标签
📸 截图