
一个简洁通用的群体智能引擎,预测万物
MiroFish是一个基于Python开发的通用型群体智能预测引擎。它利用多智能体模拟和知识图谱技术,将现实世界的“种子”信息(如新闻、报告或小说文本)转化为一个动态演化的数字平行世界。在这个虚拟环境中,成千上万个拥有记忆和个性的智能体进行自主交互,模拟社会或市场运行。用户可以通过注入不同变量,以“上帝视角”观察和推演事件未来的多种可能走向。该工具特别适用于金融预测、舆情分析、政策评估乃至创意故事的结局推演,旨在通过高保真的模拟,在风险可控的数字沙盘中为复杂决策提供前瞻性洞察。
💡 应用场景
最适合需要模拟复杂系统中多个实体(人、组织、市场因素)在互动中如何演化,从而进行预测、推演或创意生成的场景。
金融趋势预测
问题:金融分析师需要预测市场对突发新闻(如政策变动、财报发布)的复杂反应,但传统模型难以模拟群体情绪和连锁效应。
方案:将新闻、财报等作为“种子”输入MiroFish,引擎会自动创建代表不同投资者类型的智能体,模拟他们在数字世界中的互动和决策,推演市场情绪和价格走势。
示例:输入“某科技巨头发布低于预期的Q2财报”及相关行业背景,让引擎模拟散户、机构、做空者等各类市场参与者的反应,预测股价短期波动和可能的舆论焦点。
舆情危机推演
问题:企业公关团队在危机事件(如产品安全事故)爆发后,难以快速、全面地预测公众舆论的演变路径和潜在风险点。
方案:将事件通报、社交媒体初始反应等作为种子,MiroFish构建包含消费者、媒体、竞争对手、监管部门等多方角色的平行世界,推演舆论发酵、转移或升级的多种可能性。
示例:参考README中的“武汉大学舆情推演”,输入高校相关争议事件的初始报道,模拟学生、校友、公众、官方等群体的持续互动,生成舆情演变报告和风险预警。
创意内容生成与推演
问题:作家或编剧构思复杂故事时,难以确保角色行为符合其“人设”,或想探索故事线在不同关键选择下的不同结局。
方案:将小说前文或故事大纲作为种子输入,MiroFish为每个角色注入记忆与性格,让他们在模拟世界中自由交互,从而推演出符合逻辑的后续情节或多种分支结局。
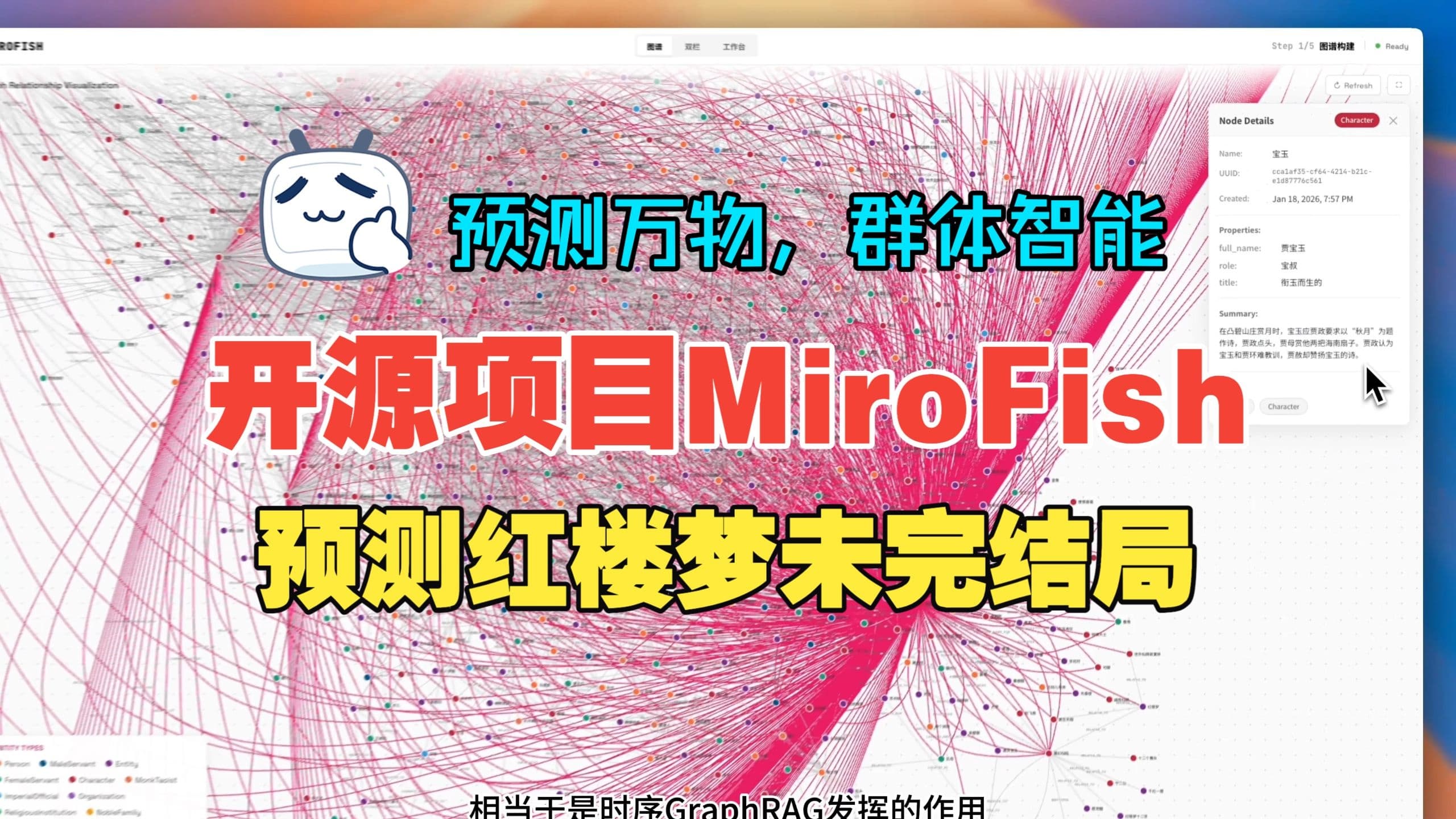
示例:如README所示,将《红楼梦》前80回文本输入,引擎能基于各人物性格和关系,推演失传后文的可能发展,为创作者提供灵感或验证剧情合理性。
政策效果沙盘模拟
问题:政府部门或智库在出台新政策(如城市规划、经济刺激)前,缺乏低成本手段预演政策对社会各阶层产生的综合影响和连锁反应。
方案:输入“某城市拟征收拥堵费”的政策草案和交通数据,模拟私家车主、公交公司、商圈、通勤者等群体的长期行为调整,预测对交通流量、商业活力、公众满意度的影响。
📊 项目信息
- 语言
- Python
- Stars
- ⭐ 62,128
- Forks
- 9,728
- 今日新增
- +197
- 排名
- #12
- 收录
- 总榜
- 趋势日期
- 2026年5月24日
- 最后推送
- 2026/5/24
🏷️ 标签
📸 截图


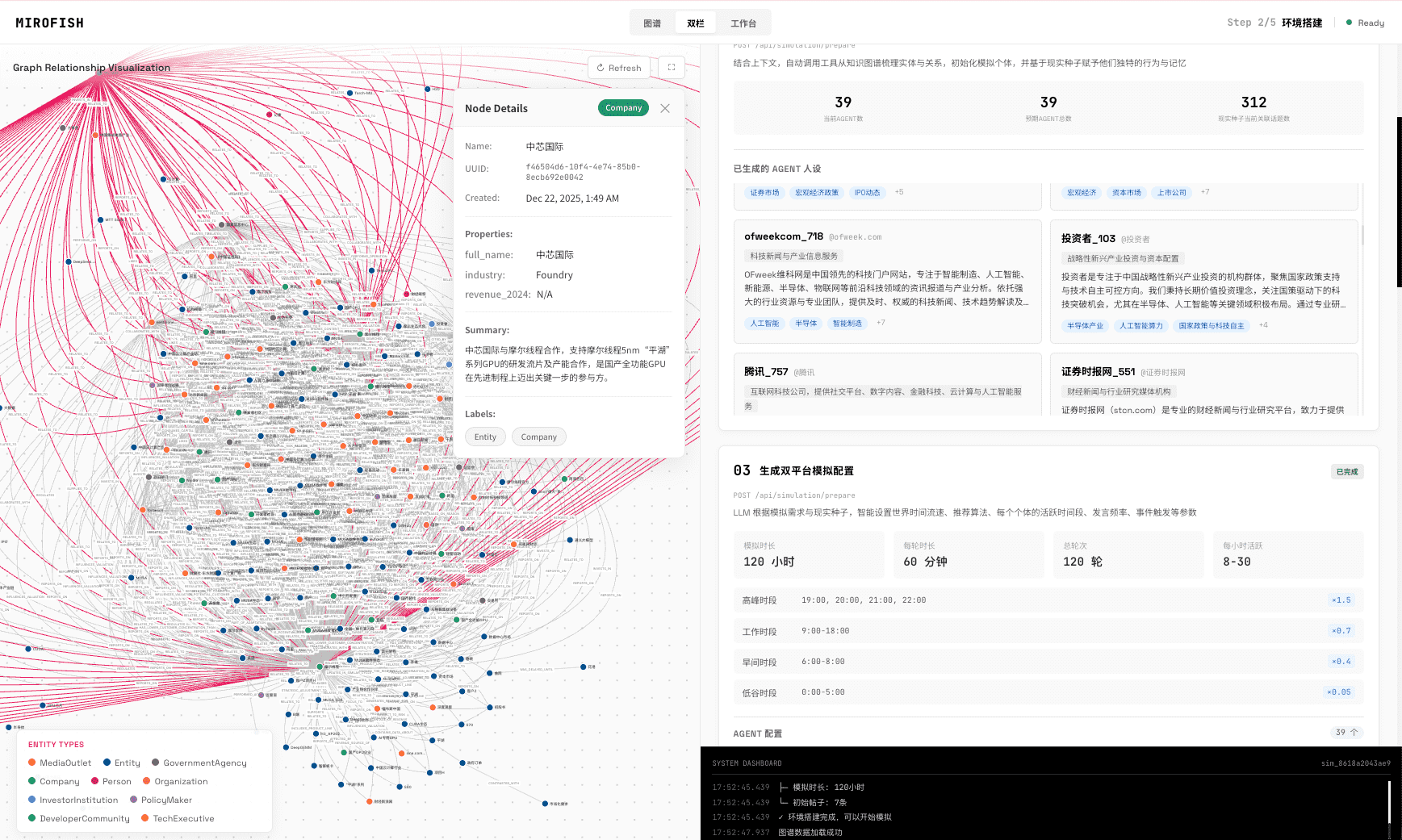
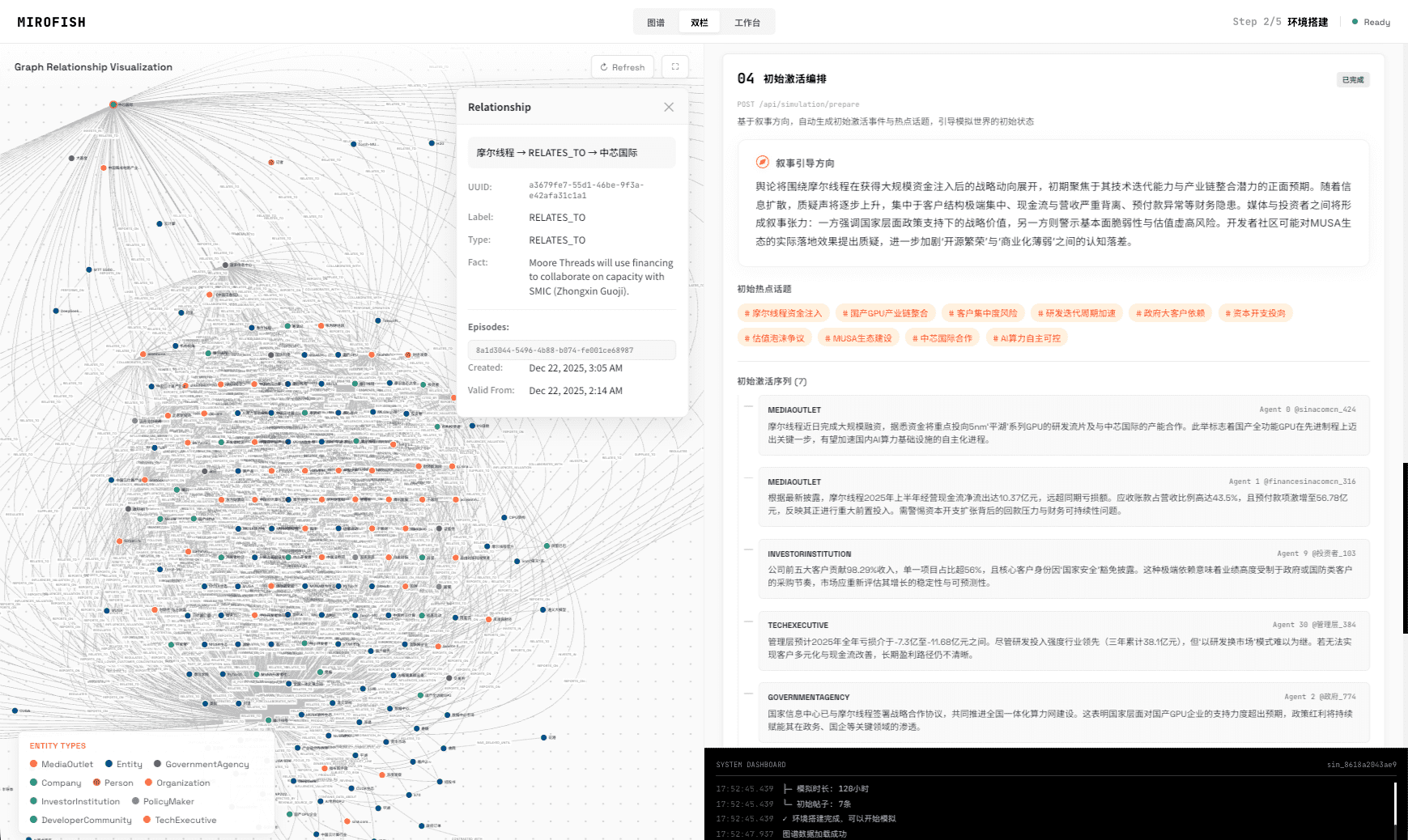
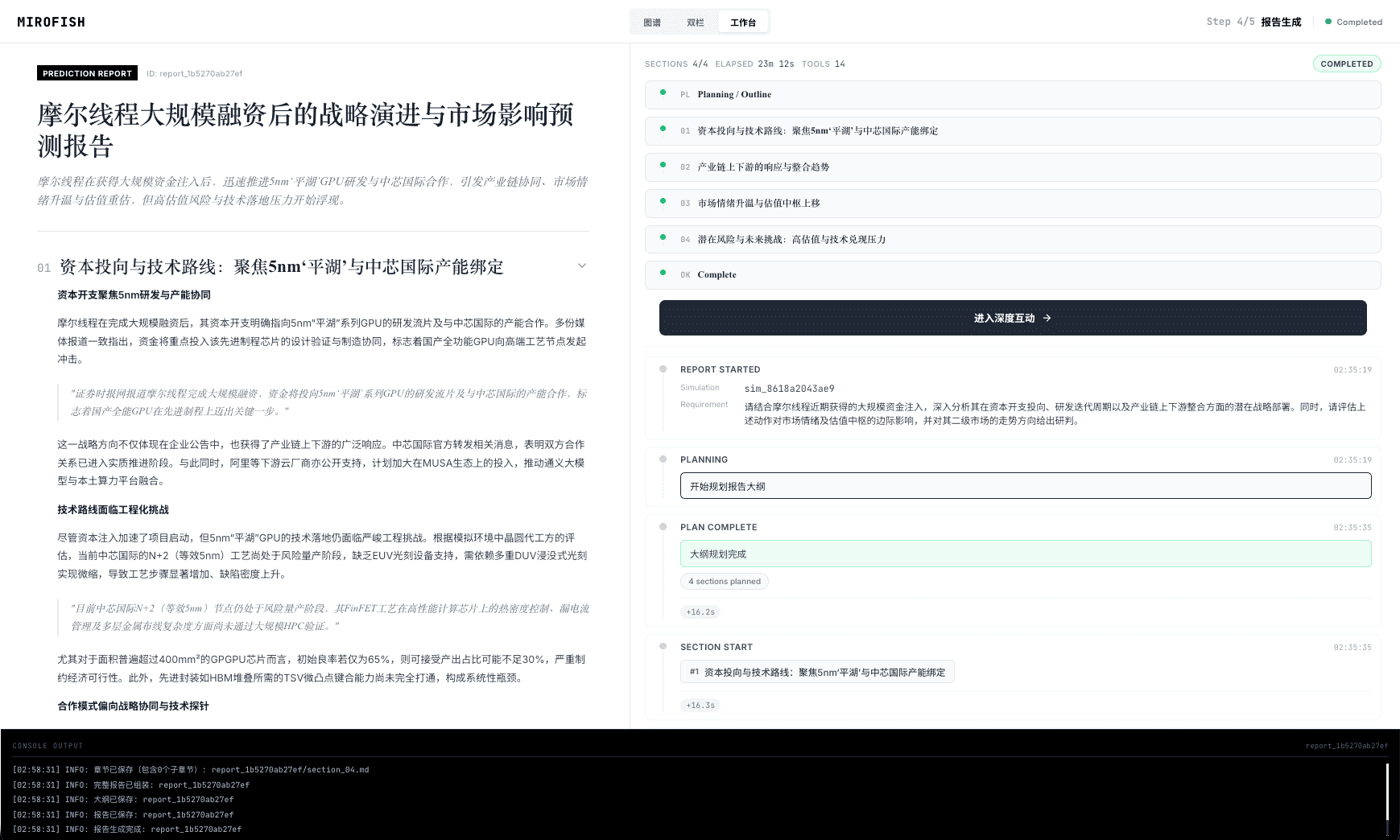
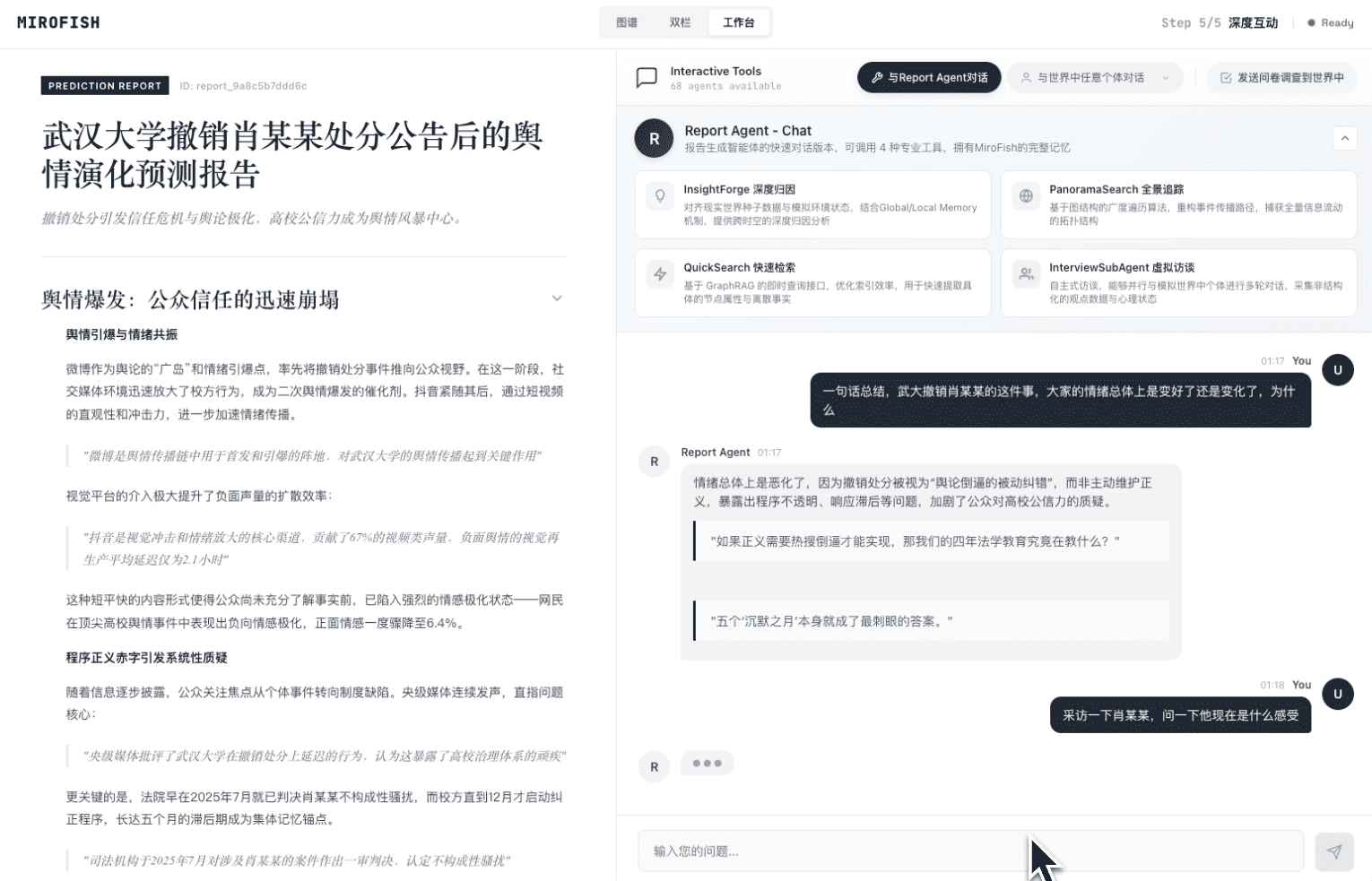
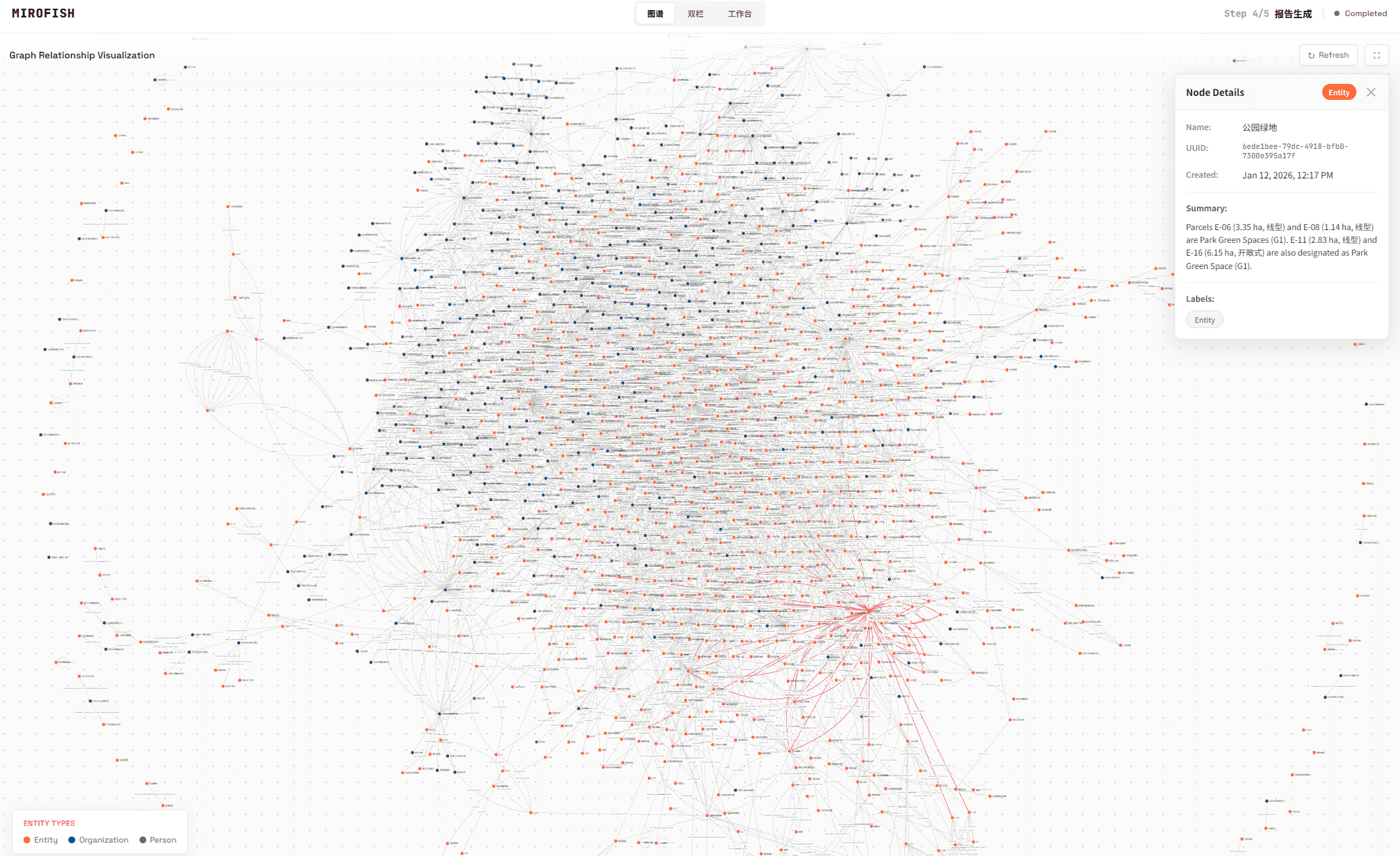


MiroFish 5分钟快速开始
快速部署MiroFish,体验群体智能预测引擎,通过模拟数字世界推演未来走向。
🖥️ 操作系统
⚙️ 运行环境
🔧 工具
📝 操作步骤
克隆项目
从GitHub克隆MiroFish源码到本地。
克隆仓库
$ git clone https://github.com/666ghj/MiroFish.git安装依赖
使用uv安装Python依赖,确保环境配置正确。
安装所有依赖
$ uv sync启动服务
启动前端和后端服务,快速运行MiroFish。
启动后端API服务
$ uv run python app.py在另一个终端启动前端服务
$ npm run dev✅ 验证部署成功
访问前端界面,确认服务正常运行。
- ✓浏览器打开 http://localhost:3000 显示MiroFish界面
- ✓后端API http://localhost:5001 返回健康状态
⚡ 快速提示
🔍 常见问题排查
❓ uv命令未找到
→ 安装uv:pip install uv
❓ 端口被占用
→ 修改.env文件中的端口号或停止占用进程
❓ Node.js版本过低
→ 升级Node.js到18或更高版本
🎯 下一步
上传种子材料
尝试上传文本如新闻或故事,进行预测推演
探索交互功能
在数字世界中与智能体对话,观察模拟结果
查看文档
访问项目文档了解更多高级用法和配置
难度
中级
预计时间
1-2天
目标人群
对多智能体系统、社会仿真或预测分析感兴趣的Python开发者、研究人员、数据分析师或技术爱好者。具备一定Python基础,希望了解如何将AI技术应用于复杂系统模拟。
🎯 学完你将掌握
能够成功部署并运行MiroFish项目,理解其基本工作流程,并能够使用自己的“种子”材料(如文本报告)进行一次基础的预测推演模拟。
📋 前置知识
项目后端使用Python开发,需要能理解基本语法、包管理和运行Python脚本。
部署和启动项目需要在终端中执行命令,如安装依赖、设置环境变量、启动服务等。
需要从GitHub克隆项目代码到本地。
项目前端基于Node.js,需要安装Node.js环境来运行前端服务。README要求版本18+。
如果选择Docker部署方式,需要了解Docker的基本概念和命令。
📚 学习资源
GitHub README
项目最核心的文档,包含概述、安装、部署、工作流程和快速开始指南。
项目演示视频(README内)
《武汉大学舆情推演预测》和《红楼梦结局推演》视频,直观展示项目能力和使用方式。
Discord 频道
README中提供的Discord链接,是与其他用户、开发者交流,获取帮助和最新动态的渠道。
Python 多智能体系统(AI Agent)入门教程
在网络上搜索关于Python AI Agent、LangChain、AutoGen的入门教程,有助于理解MiroFish的技术基础。
OpenAI API 文档 / 其他LLM提供商文档
如果项目使用了大语言模型(LLM) API,熟悉其基本调用和计费方式很重要。
🗺️ 学习阶段
环境准备与项目获取
检查并安装基础工具
按照README的“前置要求”表格,逐一检查或安装Node.js (18+)、Python (3.11-3.12) 和包管理器uv。使用命令 `node -v`, `python --version`, `uv --version` 验证安装。
克隆项目代码
使用Git命令 `git clone https://github.com/666ghj/MiroFish.git` 将项目下载到本地。
配置环境变量
在项目根目录下,参考README的“[代码块]”部分,创建并配置必要的环境变量文件(如.env)。通常需要配置API密钥(如OpenAI)等。
依赖安装与项目启动
安装Python依赖
进入项目后端目录,使用uv或pip安装所需的Python包。执行README中“[代码块]”给出的命令,例如 `uv pip install -r requirements.txt`。
安装Node.js依赖并启动前端
进入项目前端目录,运行 `npm install` 安装前端依赖。安装完成后,运行 `npm run dev` 启动前端开发服务器。
启动后端API服务
在另一个终端窗口中,进入项目后端目录,运行启动命令(如 `python app.py` 或 `uvicorn main:app --reload`)。根据README,后端通常运行在localhost:5001。
验证服务运行
打开浏览器,分别访问 `http://localhost:3000` (前端) 和 `http://localhost:5001/docs` (后端API文档,如果有的话),确认页面能正常打开。
快速体验与核心概念理解
访问在线Demo(可选但推荐)
在尝试自己的数据前,先访问README中提供的在线Demo(mirofish-live-demo),观看演示视频,直观感受系统的输入、输出和交互过程。
运行第一个示例
在成功启动的本地Web界面中,寻找示例或教程。尝试上传一个简单的“种子”文本(如README提到的《红楼梦》片段或一段简短的新闻),用自然语言描述一个简单的预测需求(如“接下来会发生什么?”),启动一次模拟。
观察工作流程
在模拟运行过程中或结束后,对照README的“工作流程”部分(图谱构建、环境搭建、开始模拟、报告生成、深度互动),尝试在界面上找到对应的环节和输出。
深入探索与调试
阅读关键代码
浏览项目的主要目录结构,重点查看负责智能体逻辑、知识图谱构建和模拟引擎的核心Python文件。不需要完全理解,但要知道核心功能在哪里实现。
查看日志与调试
学习查看前后端终端输出的日志信息。当遇到错误时,日志是定位问题最重要的依据。尝试理解常见的日志信息类型(如启动成功、API调用、错误堆栈)。
尝试修改简单配置
尝试修改环境变量(如切换不同的AI模型API)、或者在前端界面中调整一些模拟参数(如智能体数量、模拟轮数),观察对结果的影响。
⚠️ 常见错误
❌ 环境变量配置错误或缺失(特别是API密钥)。
✅ 仔细核对README和环境文件示例,确保每个必需变量都已填写正确且无拼写错误。API密钥需在对应平台申请。
❌ Python或Node.js版本不匹配。
✅ 严格使用README指定的版本范围。使用版本管理工具(如nvm for Node, pyenv for Python)可以轻松切换版本。
❌ 端口冲突导致服务启动失败。
✅ 检查3000和5001端口是否被其他程序占用。可以通过 `netstat -ano | findstr :3000` (Windows) 或 `lsof -i :3000` (Mac/Linux) 查看,并关闭占用程序或修改项目配置更换端口。
❌ 网络问题导致依赖安装失败或模型下载超时。
✅ 为pip/npm配置国内镜像源。对于需要访问海外API的服务,确保网络通畅或配置代理。
❌ 首次使用上传过大的“种子”文本,导致处理时间过长或内存溢出。
✅ 从小规模文本开始体验,例如一段200-500字的新闻摘要。熟悉流程后再尝试更大的文档。
🚀 后续方向
学完基础后可以继续探索的方向:1. **贡献代码**:阅读项目Issue列表,尝试修复简单的bug或添加小功能。2. **定制化开发**:基于MiroFish的引擎,尝试将其应用到自己的专业领域,如定制金融事件、特定游戏世界或社会现象的模拟器。3. **深入原理**:学习多智能体系统(MAS)、知识图谱、图神经网络(GNN)和强化学习的基础理论,以更深入地理解项目背后的技术。4. **性能优化**:探索如何优化大规模智能体模拟的速度和资源消耗。5. **集成与部署**:学习如何将MiroFish封装为API服务,集成到其他应用系统中,或使用Docker Compose、Kubernetes进行生产环境部署。