
DeerFlow是一个社区驱动的深度研究框架,将语言模型与网络搜索、爬取及Python执行等工具相结合,同时回馈开源社区。
DeerFlow是一个开源的多智能体编排框架,旨在构建能够执行复杂任务的“超级智能体”。它将大型语言模型与网络搜索、代码执行等多种工具能力相结合,通过协调多个具备特定技能的“子智能体”来协同工作。该框架提供了沙箱环境、长期记忆和上下文工程等核心功能,使得智能体不仅能进行信息检索和深度研究,还能安全地执行Python代码等操作。其设计强调可扩展性,允许开发者灵活集成新工具或技能。适用于需要自动化处理研究分析、内容生成、数据整合等复杂流程的场景,帮助开发者和研究者高效构建功能强大的AI应用。
💡 应用场景
最适合需要AI自动完成网络搜索、数据爬取、代码执行等多步骤复杂研究任务的场景。
深度市场调研
问题:开发者需要快速获取竞品信息、市场趋势和技术方案,但手动搜索、整理和分析耗时耗力。
方案:使用DeerFlow的搜索、爬取和Python执行能力,让AI代理自动收集网络信息,执行数据分析脚本,生成结构化报告。
示例:调研某开源项目的技术架构、社区活跃度和竞品对比,AI自动搜索GitHub、技术博客,爬取相关数据,用Python分析后输出综合报告。
自动化数据收集
问题:开发者需要定期从多个网站收集数据,但网站结构各异,手动编写和维护爬虫脚本很繁琐。
方案:利用DeerFlow的智能爬取工具和Python执行环境,AI能理解网页结构并动态调整爬取策略,自动处理反爬机制。
示例:每周自动收集电商平台商品价格、库存信息,AI识别不同网站的页面布局变化,调整爬取逻辑,将数据存入数据库。
多步骤任务编排
问题:开发者需要协调多个AI子任务(如搜索、分析、代码执行)来完成复杂工作流,但手动串联容易出错。
方案:使用DeerFlow的超级代理框架,通过配置子代理、记忆和沙箱,自动编排任务流程,确保各步骤正确衔接。
示例:先搜索最新AI论文,再爬取相关代码仓库,接着用Python分析代码质量,最后生成技术评估文档,整个过程自动执行。
安全代码执行
问题:开发者需要让AI生成并执行代码来验证想法,但直接在主机上运行未知代码有安全风险。
方案:利用DeerFlow的Docker沙箱模式,将AI生成的代码在隔离容器中安全执行,避免污染主机环境。
示例:AI根据需求生成数据处理脚本,在Docker沙箱中运行该脚本处理敏感数据,完成后自动清理容器,确保安全。
📊 项目信息
- 语言
- Python
- Stars
- ⭐ 65,520
- Forks
- 8,663
- 今日新增
- +337
- 排名
- #14
- 收录
- 总榜
- 趋势日期
- 2026年5月6日
- 最后推送
- 2026/5/6
🏷️ 标签
📸 截图

5分钟快速开始DeerFlow
DeerFlow是一个多智能体编排框架,通过Docker快速启动,构建能执行复杂任务的超级智能体。
🖥️ 操作系统
⚙️ 运行环境
🔧 工具
📝 操作步骤
克隆项目
使用Git克隆DeerFlow仓库到本地。
克隆项目
$ git clone https://github.com/bytedance/deer-flow.git生成配置文件
从项目根目录运行命令生成本地配置文件。
复制示例配置文件
$ cd deer-flow && cp config.example.yaml config.yaml配置模型和API密钥
编辑config.yaml设置模型,并在.env文件中添加API密钥。
创建.env文件并设置OpenAI API密钥
$ echo 'OPENAI_API_KEY=your_api_key_here' > .env启动Docker服务
使用Docker快速启动DeerFlow应用。
启动Docker容器
$ make docker-start✅ 验证启动成功
访问Web界面确认DeerFlow已运行。
- ✓在浏览器中打开http://localhost:2026
- ✓看到DeerFlow界面或相关响应
⚡ 快速提示
🔍 常见问题排查
❓ make docker-start命令失败
→ 检查Docker是否安装并运行,尝试docker-compose up手动启动。
❓ 无法访问http://localhost:2026
→ 确认服务已启动,检查防火墙或网络设置。
❓ API密钥错误导致模型无法调用
→ 验证.env文件中的API密钥是否正确,并确保有足够额度。
🎯 下一步
探索内置技能
尝试使用DeerFlow进行Web搜索或代码执行等任务。
查看官方文档
访问deerflow.tech了解更多功能和高级配置。
加入社区
参与GitHub讨论,获取帮助和分享经验。
难度
中级
预计时间
1-2天
目标人群
具备基础Python和命令行知识的开发者,对AI智能体、LangChain/LangGraph有一定了解或兴趣,希望构建自动化复杂任务应用的研究者或工程师。
🎯 学完你将掌握
你将能够配置并运行DeerFlow框架,理解其核心概念(智能体、技能、沙箱),并利用它创建一个能执行多步骤任务(如研究、报告生成)的AI应用。
📋 前置知识
DeerFlow是Python项目,需要能理解基本语法、包管理和虚拟环境。
需要运行git、docker、make等命令来克隆项目、启动服务。
用于克隆项目仓库。
项目推荐使用Docker运行,需要知道如何安装Docker和运行容器。
了解大型语言模型(LLM)、API密钥、提示词等基本概念,有助于理解框架工作原理。
📚 学习资源
DeerFlow 官方网站与Demo
deerflow.tech,查看实际演示和更生动的介绍。
项目README.md
最核心的指南,包含快速开始、核心概念和配置说明。
Configuration Guide 与 Architecture Overview
在项目文档目录中,深入了解配置细节和技术架构。
GitHub Issues 和 Discussions
遇到问题时在此搜索或提问,查看社区的热点问题和解决方案。
LangChain/LangGraph 官方教程
DeerFlow 2.0基于它们构建,了解其基础有助于深入理解框架原理。
🗺️ 学习阶段
环境准备与项目初探
安装基础软件
确保你的电脑已安装:1. Git。2. Python (3.10+)。3. Docker Desktop (推荐) 或 Docker Engine。
克隆项目并浏览结构
使用 `git clone https://github.com/bytedance/deer-flow.git` 克隆项目到本地。打开项目文件夹,快速浏览README和目录结构,了解核心文件如 `config.yaml`, `.env.example`, `docker-compose.yml`。
核心配置与首次运行
生成配置文件
在项目根目录运行命令(根据README),从模板生成本地配置文件 `config.yaml` 和 `.env`。
配置LLM模型和API密钥
1. 编辑 `config.yaml`,在 `models` 部分至少配置一个你拥有的LLM(如OpenAI GPT-4o, Anthropic Claude等)。2. 编辑 `.env` 文件,填入对应模型的API密钥。这是项目运行的关键。
使用Docker一键启动
在项目根目录运行 `make docker-start` 或 `docker-compose up`(根据README指示)。等待所有服务(后端、前端、可能需要的provisioner)启动完成。
访问Web界面
打开浏览器,访问 `http://localhost:2026`。如果看到DeerFlow的Web界面,恭喜你,环境搭建成功!
概念理解与基础交互
理解核心概念
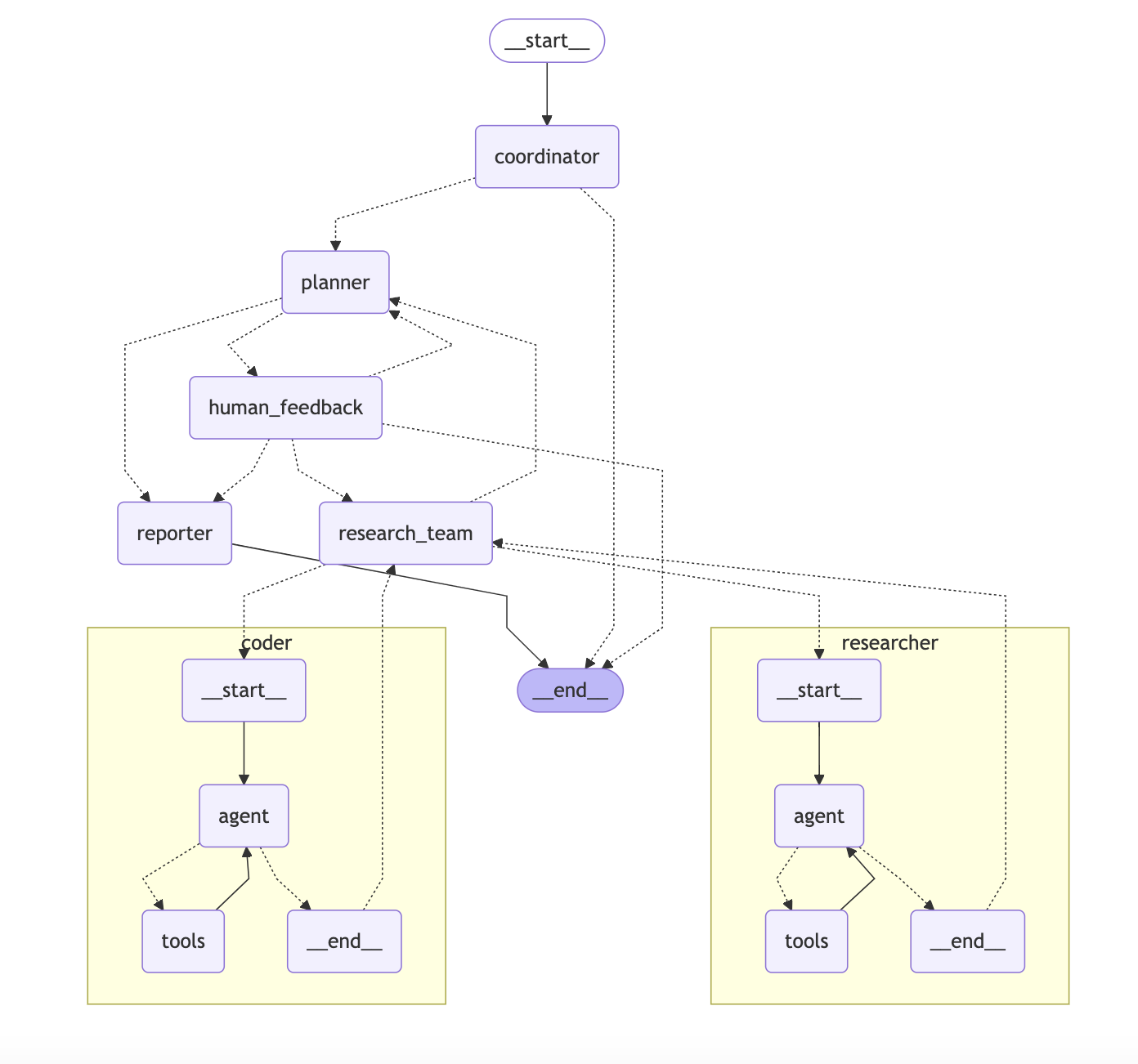
阅读README的“Core Features”部分,重点理解:1. **Skills & Tools**:智能体能做什么。2. **Sub-Agents**:任务如何分解。3. **Sandbox & File System**:代码在哪里安全执行。4. **Context & Memory**:如何管理信息。
运行第一个简单任务
在Web界面中,尝试输入一个简单的任务,例如:“请用中文介绍一下你自己”或“总结今天的主要科技新闻”。观察智能体如何规划、调用工具(如搜索)、并返回结果。
探索沙箱与文件系统
尝试一个涉及文件操作或代码执行的任务,例如:“创建一个名为hello.txt的文件,并写入‘Hello DeerFlow’,然后列出当前目录文件”。在Web界面中查看生成的文件和命令执行结果。
深入技能与配置
查看内置技能(Skills)
在项目代码中查找 `skills/` 目录,浏览里面的 `.md` 文件。了解一个技能如何定义工作流、使用工具和最佳实践。例如,查看 `research.md` 或 `generate_report.md`。
修改配置体验不同模式
根据“Sandbox Mode”指南,尝试修改 `config.yaml` 中的 `sandbox.mode` 设置(例如从 `docker` 改为 `local`,需谨慎),理解不同执行模式的区别。修改后需重启服务。
尝试一个复杂任务
输入一个更复杂的多步骤任务,如:“研究一下大语言模型在2024年的主要进展,并生成一份包含关键点和引用的简短Markdown报告”。观察主智能体如何创建子智能体分工合作,并最终合成报告。
⚠️ 常见错误
❌ API密钥配置错误或未配置
✅ 确保在 `.env` 文件中填写的变量名与 `config.yaml` 中 `model` 配置的 `api_key_env_var` 字段完全一致,并且值正确。重启服务使配置生效。
❌ Docker端口冲突或权限问题
✅ 检查本地端口2026是否已被其他程序占用。在Linux/Mac上,如果Docker需要sudo权限,确保以正确方式运行,或将用户加入docker组。
❌ 未理解沙箱模式配置
✅ 新手请严格遵循README的Docker启动方式。不要随意更改 `sandbox.mode` 为 `local`,除非你清楚知道代码将在你的主机上直接执行带来的安全风险。
❌ 任务描述过于模糊
✅ 给智能体的指令应尽量清晰、具体。例如,“写一篇博客”不如“写一篇关于DeerFlow入门指南的博客,面向Python开发者,字数800左右”效果好。
❌ 忽略查看容器日志
✅ 当服务启动失败或任务执行出错时,第一时间使用 `docker-compose logs` 或 `docker logs <container_name>` 查看具体错误信息,这是调试的最重要依据。
🚀 后续方向
1. **技能开发**:参考现有技能格式,为你自己的领域(如数据分析、社交媒体管理)创建自定义技能。2. **工具集成**:通过MCP服务器或Python函数集成新的工具(如数据库、内部API)。3. **研究架构**:阅读Architecture Overview和源码,理解LangGraph状态图如何驱动智能体协作。4. **参与贡献**:按照CONTRIBUTING.md指南,从修复文档错别字、增加测试或实现一个小功能开始,参与开源社区。5. **构建应用**:尝试将DeerFlow作为引擎,嵌入到你自己的Python应用或Web服务中,解决实际的自动化需求。