开源前沿语音人工智能
💡 应用场景
最适合需要处理长音频、多语言、实时语音交互的开发者场景。
长会议录音转文字
问题:开发者需要将长达60分钟的会议录音转换成带时间戳和说话人标识的结构化文字稿。
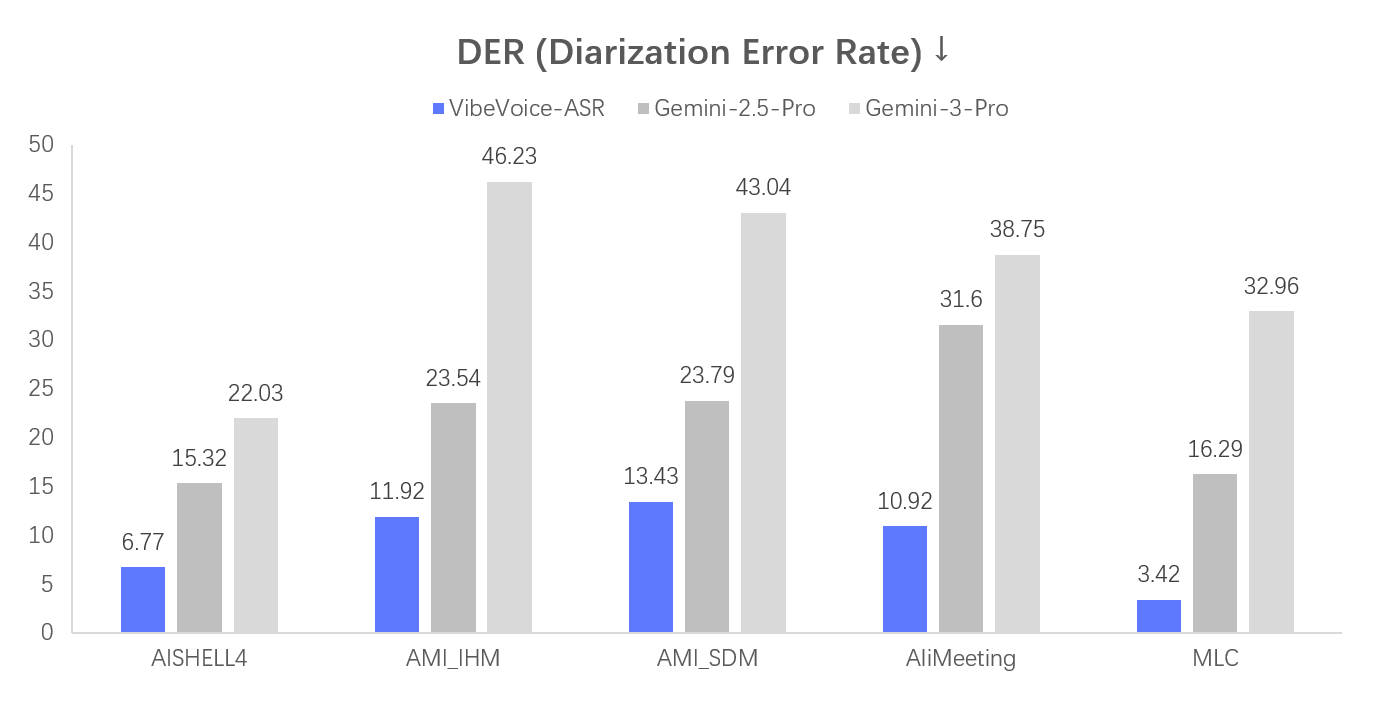
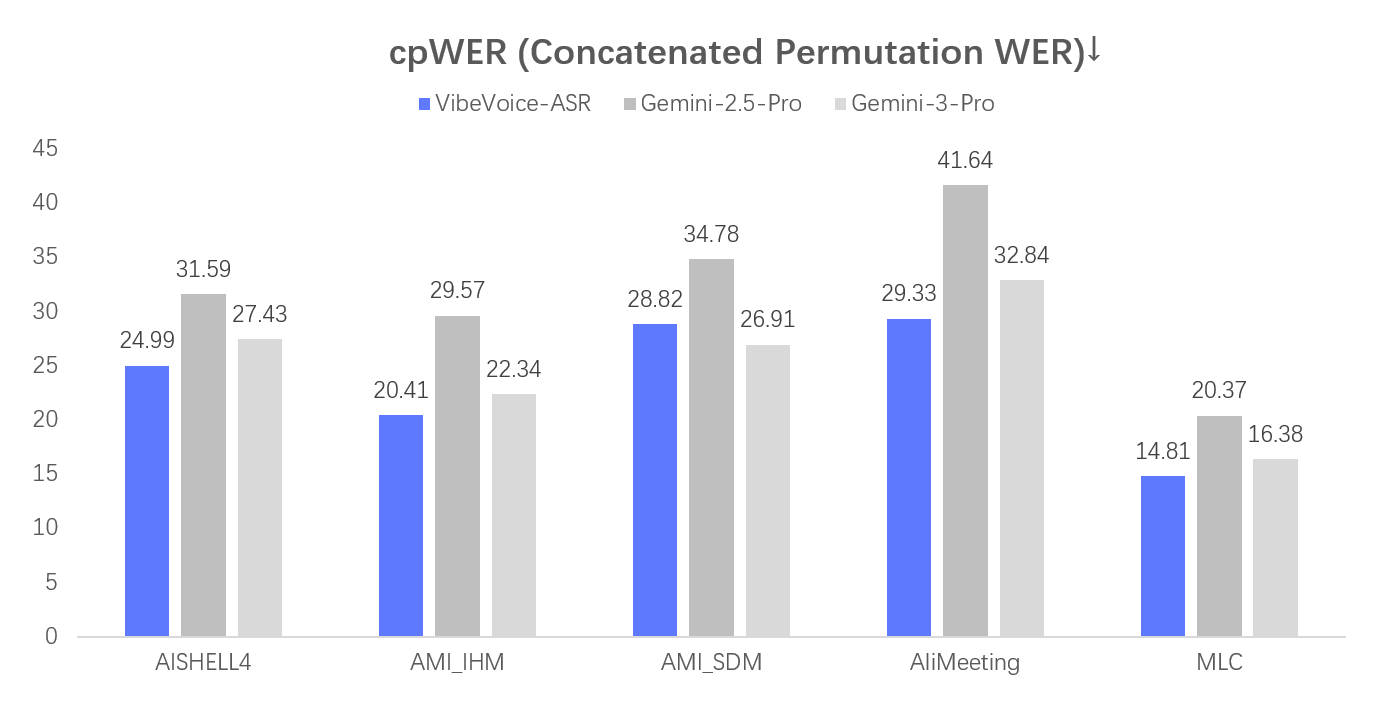
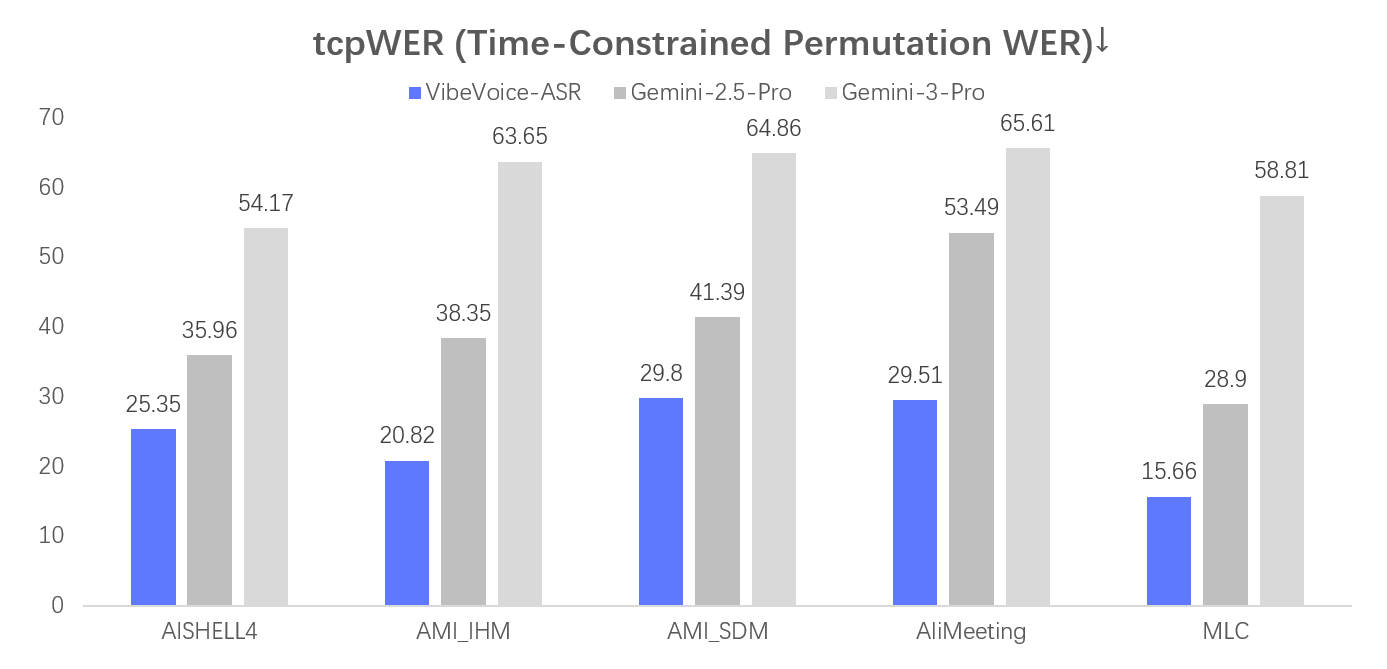
方案:使用VibeVoice-ASR模型,它能单次处理60分钟长音频,自动生成包含说话人、时间戳和内容的完整转录。
示例:将团队周会录音上传,模型自动输出“09:15-12:30 张三:关于Q2目标... 12:31-15:45 李四:我建议...”的结构化会议纪要。
实时语音助手开发
问题:开发者想为应用添加实时语音交互功能,需要低延迟的语音识别和语音合成。
方案:结合VibeVoice-ASR进行实时语音识别,并使用VibeVoice-Realtime-0.5B进行流式文本到语音的实时合成。
示例:开发智能客服应用,用户说话时实时转文字,AI回复时立即用自然语音播报,支持多语言交互。
多语言播客生成
问题:内容创作者需要将文字稿转换成多种语言、多种风格的自然语音播客。
方案:使用VibeVoice-Realtime-0.5B的多语言和多种风格语音合成能力,快速生成不同语言的播客音频。
示例:将一篇英文文章分别转换成德语、法语、日语播客,并可选择新闻播报、故事讲述等不同语音风格。
长视频字幕生成
问题:视频创作者需要为长达数小时的视频教程或纪录片自动生成准确的字幕文件。
方案:利用VibeVoice-ASR支持50多种语言的特性,批量处理长视频音频,输出带时间戳的SRT字幕文件。
示例:将2小时的编程教学视频上传,模型自动生成中英文字幕,准确识别技术术语和说话人切换。
📊 项目信息
- 语言
- Python
- Stars
- ⭐ 30,116
- Forks
- 3,309
- 今日新增
- +2,492
- 排名
- #1
- 收录
- 总榜
- 趋势日期
- 2026年3月30日
- 最后推送
- 2026/3/29
📸 截图