
一个使用大语言模型从非结构化文本中提取结构化信息的Python库,具备精确的源数据溯源和交互式可视化功能。
LangExtract是一个基于大语言模型的Python库,专门用于从非结构化的文本中自动提取结构化的信息。它允许用户通过提供少量示例来定义需要提取的数据类型和格式,随后库便能处理如临床记录、报告等长文档,精准识别并整理出关键细节。其核心优势在于确保所有提取出的数据都能精确追溯到原文中的具体位置,并支持生成交互式可视化文件以供审核。该工具采用优化的文本分块与并行处理策略,能高效应对海量文本,同时支持多种大语言模型,包括谷歌Gemini系列云端模型和通过Ollama部署的本地开源模型,无需微调即可灵活适配各种专业领域的复杂信息抽取任务。
💡 应用场景
最适合需要从大量非结构化长文档中,快速、准确提取特定结构化信息,且要求结果可追溯和审核的场景。
医疗报告结构化
问题:医生或研究人员需要从海量非结构化的临床记录或病历报告中,快速提取出关键的药物、剂量、诊断结果等信息,手动整理耗时且易出错。
方案:使用LangExtract定义药物提取任务,提供少量示例后,即可批量处理临床文档,自动生成结构化的药物清单,并精确定位到原文位置供审核。
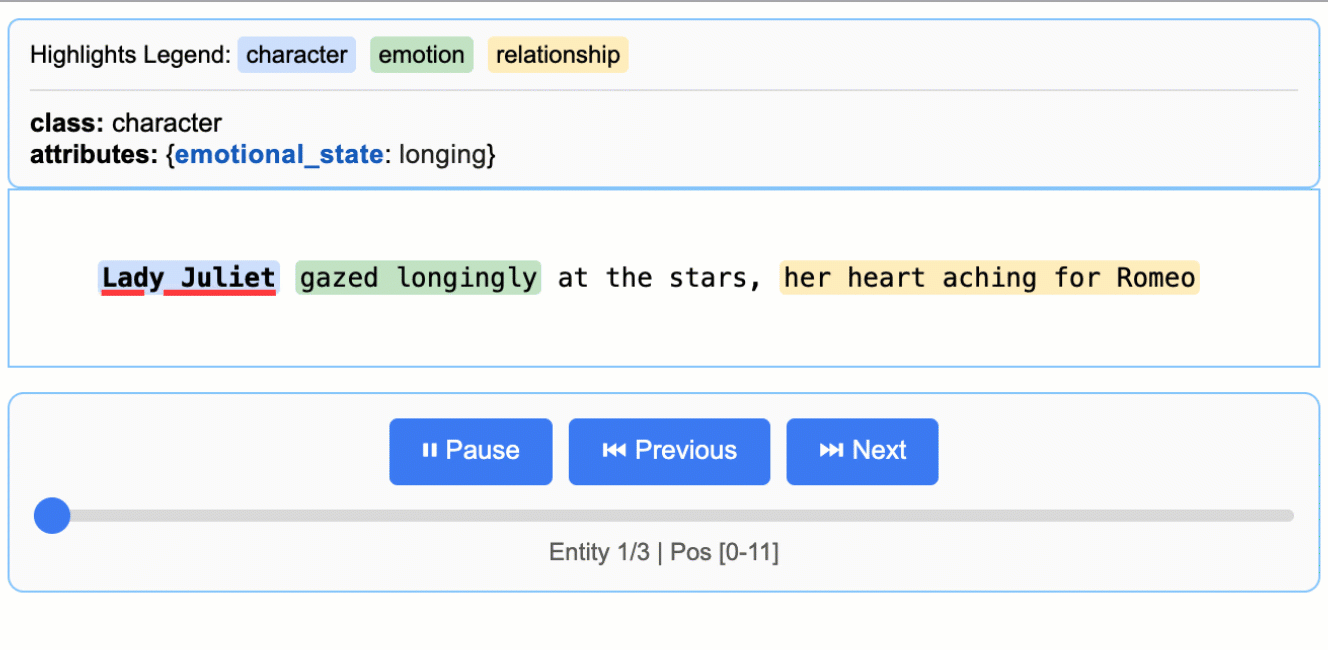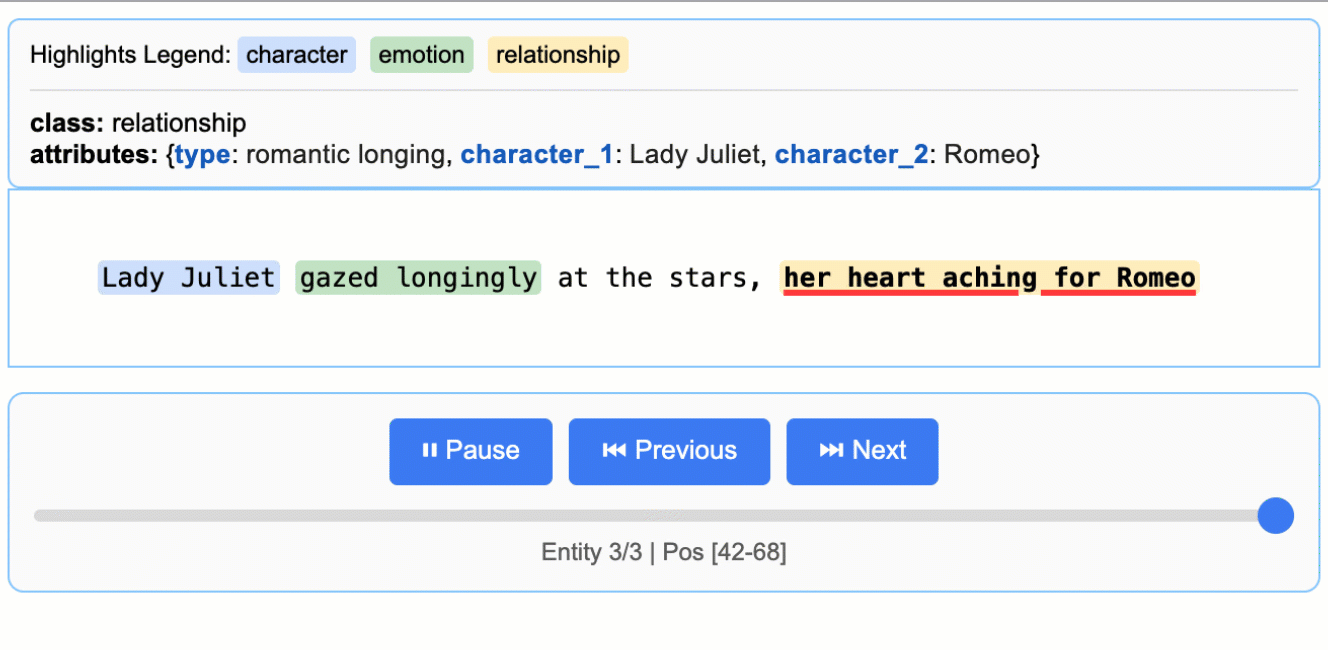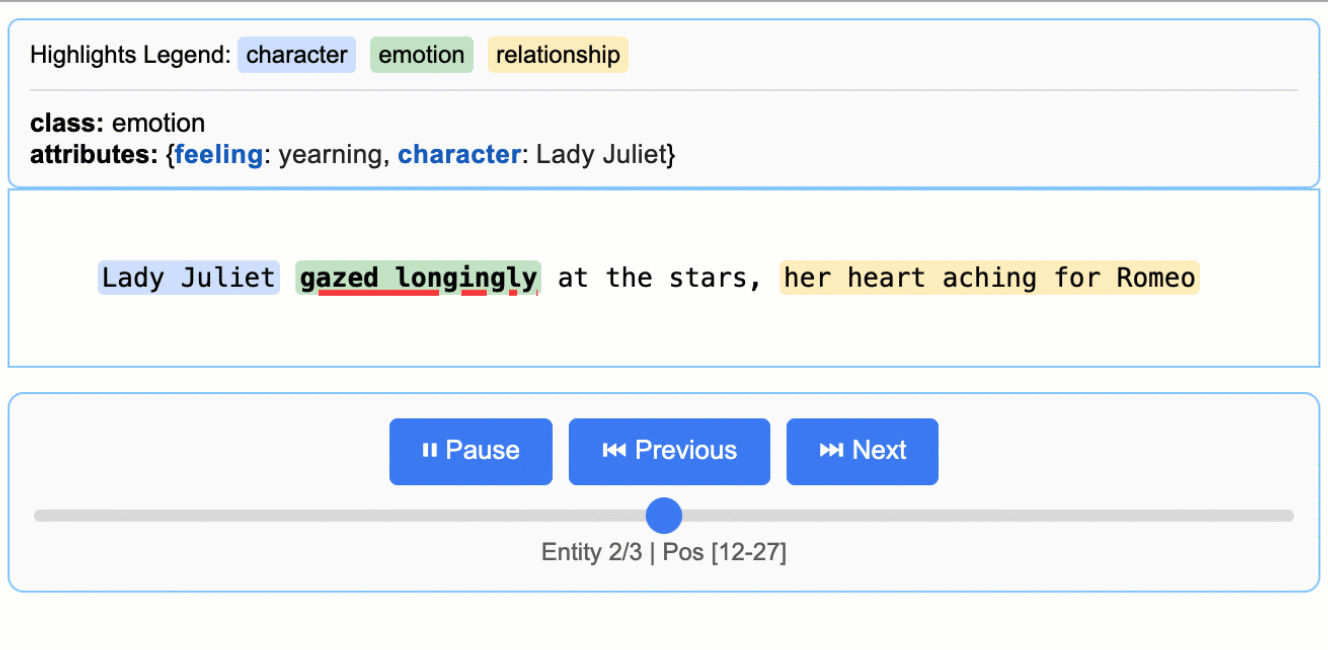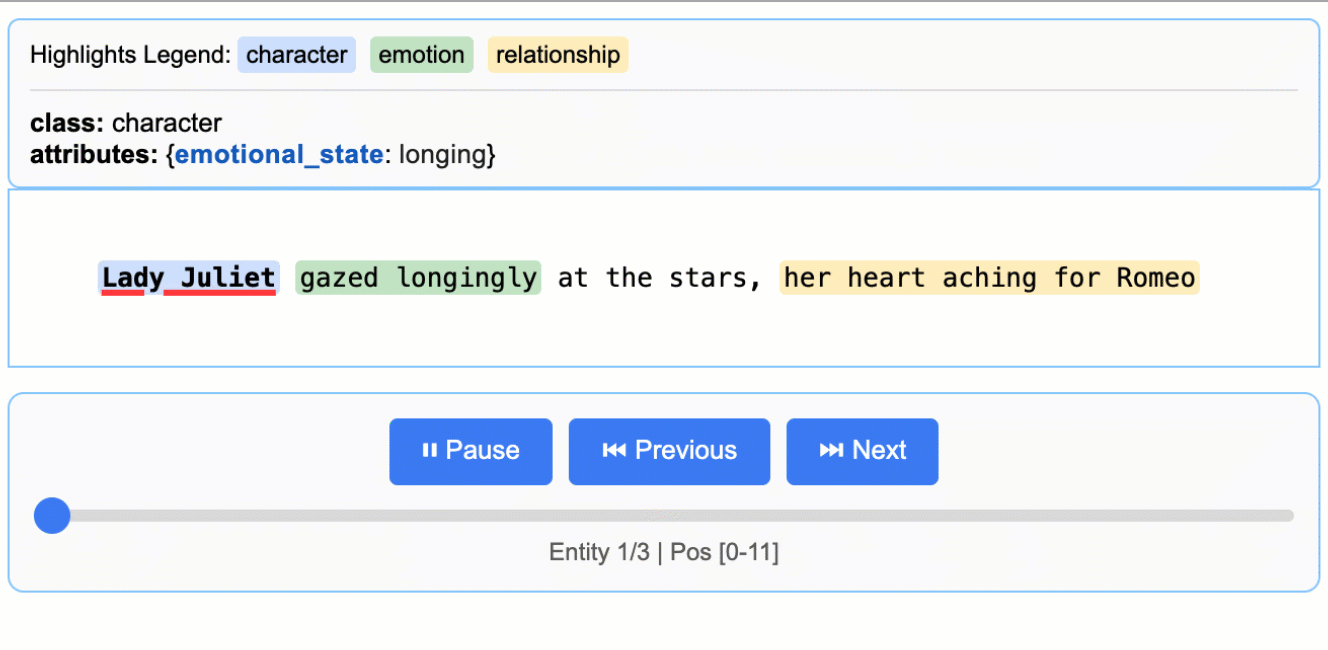
示例:如README中的'Medication Extraction'示例,从临床笔记中提取药物名称、剂量、频率和给药途径,生成可交互的HTML文件进行可视化验证。
法律合同信息抽取
问题:法务或合规团队需要审阅大量合同文本,从中找出关键条款(如签约方、金额、有效期、违约责任),人工阅读效率低下。
方案:通过定义合同要素的提取模板,LangExtract能自动扫描长文档,识别并结构化关键条款,确保每个提取项都能追溯到合同原文的具体条款。
示例:处理一份50页的租赁合同,自动提取出租人、承租人、租金、租期、押金等字段,生成结构化JSON数据并附带原文高亮。
学术文献元数据整理
问题:研究者需要从成百上千篇PDF格式的学术论文中,批量提取标题、作者、摘要、关键词等元数据,手动复制粘贴工作繁重。
方案:利用LangExtract的文本分块和并行处理能力,快速处理大量文献,根据定义的元数据格式自动抽取信息,支持本地Ollama模型以保护数据隐私。
示例:从生物医学论文集中,自动提取研究目的、方法、主要发现和结论,构建可供后续分析的数据库。
客户反馈分析自动化
问题:产品经理需要从杂乱无章的客户反馈(邮件、评论、调查文本)中,系统性地提取产品问题、功能请求和情感倾向,缺乏自动化工具。
方案:配置提取任务,让LangExtract从非结构化反馈中识别问题类型、严重程度和具体描述,生成结构化报告并可视化高频问题。
示例:分析1000条用户评论,自动分类出'登录问题'、'支付失败'、'UI建议'等类别,并统计出现频率,定位原文片段。
📊 项目信息
- 语言
- Python
- Stars
- ⭐ 22,669
- Forks
- 1,562
- 今日新增
- +652
- 排名
- #2
- 收录
- 总榜
- 趋势日期
- 2026年1月19日
🏷️ 标签
📸 截图
5分钟上手 LangExtract
通过本指南,您将快速安装 LangExtract 并运行第一个文本信息提取示例,体验从非结构化文本中提取结构化数据的过程。
🖥️ 操作系统
⚙️ 运行环境
🔧 工具
📝 操作步骤
安装 LangExtract
使用 pip 从 PyPI 安装最新版本的 LangExtract。建议在虚拟环境中操作。
安装核心库
$ pip install langextract设置 API 密钥(使用云端模型)
要使用默认的 Gemini 模型,您需要一个 Google AI Studio 的 API 密钥。这是运行示例的关键一步。
在 Linux/macOS 终端中设置环境变量
$ export GOOGLE_API_KEY="YOUR_API_KEY"在 Windows 命令提示符中设置环境变量
$ set GOOGLE_API_KEY=YOUR_API_KEY运行第一个提取示例
创建一个简单的 Python 脚本,定义提取任务并处理一段文本。
✅ 验证成功
运行示例脚本后,检查以下两点以确认安装和配置成功:
- ✓控制台打印出提取到的结构化信息(一个包含 `text` 和 `attributes` 的字典列表)。
- ✓当前目录下生成了 `my_first_extraction.jsonl` 文件。
⚡ 快速提示
🔍 常见问题排查
❓ 运行脚本时报错:`google.api_core.exceptions.PermissionDenied: 403 ... API key not valid. Please pass a valid API key.`
→ API 密钥无效或未正确设置。请确认:1) 密钥从 Google AI Studio 获取且未过期;2) 环境变量名是 `GOOGLE_API_KEY`;3) 在运行脚本的终端中已设置该变量。
❓ 安装失败,提示 `Could not find a version that satisfies the requirement langextract` 或类似错误。
→ 请确保 pip 已更新 (`pip install --upgrade pip`),并且 Python 版本 >= 3.8。也可以尝试指定 PyPI 源:`pip install langextract -i https://pypi.org/simple`。
❓ 运行提取时速度很慢或没有输出。
→ 可能是网络问题或模型服务暂时不可用。可以尝试:1) 检查网络连接;2) 稍后重试;3) 考虑使用本地模型(如通过 Ollama)以避免网络依赖。
🎯 下一步
生成交互式可视化报告
使用 `lx.visualize` 函数,将上一步生成的 `.jsonl` 文件转换为一个可交互的 HTML 文件,在浏览器中查看高亮显示的提取结果。
尝试处理长文档或 URL
修改脚本,将 `input_text` 替换为一个长文本字符串或一个 URL(如 `input_text = lx.utils.read_url('https://...')`),体验库对长文档的优化处理能力。
探索更多示例
查看项目 README 中的 `More Examples` 部分,运行如“罗密欧与朱丽叶”全文提取或药物提取等更复杂的示例。
难度
初级
预计时间
3-5小时
目标人群
具备基本Python编程能力,对自然语言处理和大语言模型感兴趣的数据分析师、数据科学家、软件开发者或学生。无需深度学习或NLP专业知识。
🎯 学完你将掌握
能够使用LangExtract库从任意非结构化文本(如报告、小说、临床记录)中提取结构化信息,并生成可交互的可视化结果进行审核。
📋 前置知识
需要能够安装Python包、编写简单的Python脚本、理解函数调用和数据结构(如列表、字典)。因为LangExtract是一个Python库。
需要能够在终端中运行命令,用于安装Python包、设置环境变量等。
知道什么是大语言模型(如ChatGPT、Gemini)以及API Key的作用,有助于理解库的工作原理和配置。
📚 学习资源
GitHub README
本项目最核心的文档,包含了从安装、配置、快速入门到高级功能的所有说明。
PyPI项目页面
查看库的最新版本和最基本的安装命令。
GitHub Issues 和 Discussions
遇到问题时可以在这里搜索是否已有解决方案,或提出新问题。也可以看看其他用户的使用案例。
Google AI Studio / OpenAI Platform 文档
当需要配置Gemini或OpenAI API Key时,这些平台的官方文档是获取密钥和了解配额、费率的最佳地点。
🗺️ 学习阶段
环境准备与安装
安装Python和包管理工具
确保你的电脑上安装了Python(建议3.9或更高版本)和pip。可以在终端输入 `python --version` 和 `pip --version` 来检查。
安装LangExtract库
在终端中运行命令 `pip install langextract` 来从PyPI安装库。这是最推荐的方式。
获取并设置API Key(如需使用云端模型)
如果你计划使用Google Gemini或OpenAI等云端模型,需要去相应平台(如AI Studio)获取API Key。然后创建一个名为 `.env` 的文件,在里面写入 `GOOGLE_API_KEY=你的密钥`。在代码中通过 `load_dotenv()` 加载。
快速入门:第一个提取任务
理解核心概念:提示(Prompt)和示例(Examples)
仔细阅读README中“Define Your Extraction Task”部分。理解如何通过一段文字描述(Prompt)和几个具体的输入-输出对(Examples)来定义一个提取任务。这是LangExtract工作的核心。
运行第一个提取示例
复制README“Quick Start”部分的代码块到你的Python脚本中。使用默认的 `gemini-2.5-flash` 模型运行。观察输出结果,理解返回的数据结构。
生成并查看可视化结果
运行代码中将结果保存为JSONL文件并生成HTML可视化的部分。在浏览器中打开生成的HTML文件,体验交互式高亮和追溯功能。
核心功能探索
尝试处理长文档
按照“Scaling to Longer Documents”部分的示例,尝试从一个URL(如公开的小说文本)加载长文档进行提取。注意代码中 `parallel=True` 和 `sensitivity=‘high’` 的参数设置。
探索不同的模型
1. 尝试使用OpenAI模型:先安装可选依赖 `pip install langextract[openai]`,然后参考“Using OpenAI Models”部分的代码进行配置。注意所需的参数(`fenceoutput=True`)。 2. 尝试使用本地Ollama模型:按照README对应部分,先安装并启动Ollama,拉取一个模型(如llama3.2),然后在LangExtract中指定模型名称(如 `‘ollama/llama3.2’`)。
定义你自己的提取任务
选择一个你感兴趣的领域(如从新闻中提取事件要素、从商品评论中提取观点和实体),模仿快速入门的格式,自己编写Prompt和1-2个高质量示例,然后对一段新的文本进行提取。
进阶了解与调试
理解错误和警告信息
在实验过程中,你可能会遇到“Prompt alignment”警告、API速率限制错误、模型不支持某种格式等。学习查阅错误信息,并回到README或相关文档寻找解决方案。
浏览更多示例项目
访问GitHub仓库中的 `examples/` 目录(如果提供),运行如“Romeo and Juliet Full Text Extraction”、“Medication Extraction”等更复杂的示例。学习它们如何构建复杂的提取逻辑。
了解高级功能(可选)
阅读README中关于“Vertex AI Batch Processing”(用于大规模处理节省成本)和“Adding Custom Model Providers”(添加自定义模型)的部分,了解其概念和基本用法。
⚠️ 常见错误
❌ API Key未正确设置或环境变量未加载
✅ 确认在 `.env` 文件中正确写入 `GOOGLE_API_KEY=你的密钥`,并在Python脚本最开头调用 `load_dotenv()`。可以通过 `print(os.getenv('GOOGLE_API_KEY'))` 测试是否加载成功。
❌ 提供的示例(Examples)质量不高
✅ 确保每个示例中的 `extractiontext` 字段是原文的**逐字复制**,而不是概括或转述,并且多个提取项的顺序与它们在原文中出现的顺序一致。遵循这个模式可以避免警告并获得更好结果。
❌ 直接使用OpenAI模型时未设置必要参数
✅ 使用OpenAI模型时,必须在 `lx.extract` 函数中设置 `fenceoutput=True` 和 `useschemaconstraints=False`,因为当前版本对OpenAI的结构化输出支持方式不同。
❌ 处理超长文本时超出模型上下文长度或API配额
✅ LangExtract会自动分块处理,但也要注意单次请求的总体文本量。对于大规模任务,考虑启用Vertex AI批处理API,或使用本地模型。同时关注云模型的每秒请求数(RPM)和每分钟令牌数(TPM)限制。
❌ 期望模型进行过多“推理”而非“提取”
✅ LangExtract的核心是“基于原文的提取”。如果你的Prompt要求模型生成大量原文中没有明确表述的信息(依赖世界知识),效果可能不稳定。调整Prompt,更侧重于“从下面文字中找出...”,并提供相应的示例。
🚀 后续方向
1. **实战项目**:将LangExtract应用到你自己的数据上,如分析公司报告、整理研究论文摘要、处理客户反馈等,解决一个真实问题。 2. **性能优化**:学习使用批处理(Vertex AI Batch)来处理海量文档,优化成本和速度。 3. **模型深度探索**:尝试集成更多本地或小众的LLM(通过自定义Provider),或比较不同模型在你特定任务上的表现。 4. **贡献社区**:如果发现了Bug或有改进想法,可以阅读CONTRIBUTING指南,向开源项目提交Issue或Pull Request。 5. **学习相关领域**:深入了解提示工程(Prompt Engineering)、信息抽取(Information Extraction)等NLP概念,以更好地驾驭此类工具。