
CUDA Templates and Python DSLs for High-Performance Linear Algebra
💡 Use Cases
CUTLASS最适合需要在NVIDIA GPU上快速开发或集成高性能、定制化线性代数计算(尤其是矩阵乘法及其变体)的场景。
自定义高效GEMM内核
Problem: 开发者需要实现特定数据格式(如混合精度、窄整数)的高性能矩阵乘法,但直接编写CUDA代码复杂且难以优化。
Solution: 使用CUTLASS的C++模板库,通过组合预定义的模块化组件(如tiling策略、数据搬运抽象),快速构建针对特定硬件(如Tensor Core)优化的GEMM内核。
Example: 为推理引擎实现INT4权重的矩阵乘法,利用CUTLASS对窄整数类型的支持,快速组装出在Ampere架构上高效运行的内核。
快速原型新算法
Problem: 研究人员想验证新的线性代数算法(如特殊分解或稀疏计算)在GPU上的性能,但底层CUDA编程门槛高、编译慢。
Solution: 使用CUTLASS 4新增的CuTe DSL(Python接口),用更直观的语法描述计算和数据布局,无需深入C++即可快速编写和测试高性能CUDA内核。
Example: 在Hopper GPU上尝试一种新的混合精度(FP16累加到FP32)卷积算法,用CuTe DSL几天内完成原型和性能评测,而传统方式可能需要数周。
集成定制算子到DL框架
Problem: 深度学习框架(如PyTorch)缺少某个专用算子(如基于MXFP8数据类型的注意力计算),需要高性能实现且易于集成。
Solution: 用CuTe DSL编写算子内核,它天然支持与DL框架交互,无需编写胶水代码,编译出的高效CUDA内核可直接被框架调用。
Example: 为大型语言模型添加支持OCP标准MXFP4数据类型的线性层,用CuTe DSL实现内核并封装为PyTorch扩展,显著降低部署内存。
教学与学习GPU编程
Problem: 学生或新手想理解GPU上高性能矩阵计算的核心概念(如层次化分解、数据搬运),但纯CUDA示例过于底层和冗长。
Solution: 利用CUTLASS良好抽象的C++组件或更友好的CuTe DSL,通过修改参数(如分块大小、数据布局)来直观学习不同优化策略的影响。
Example: 在课程实验中,让学生用CuTe DSL调整GEMM的Tile大小和Shared Memory使用,观察性能变化,从而理解GPU内存层次的作用。
📊 Project Info
- Language
- C++
- Stars
- ⭐ 9,797
- Forks
- 1,876
- Today
- +7
- Ranking
- #1
- Collection
- Language
- Trending Date
- May 27, 2026
- Last Push
- 5/27/2026
🏷️ Topics
📸 Screenshots

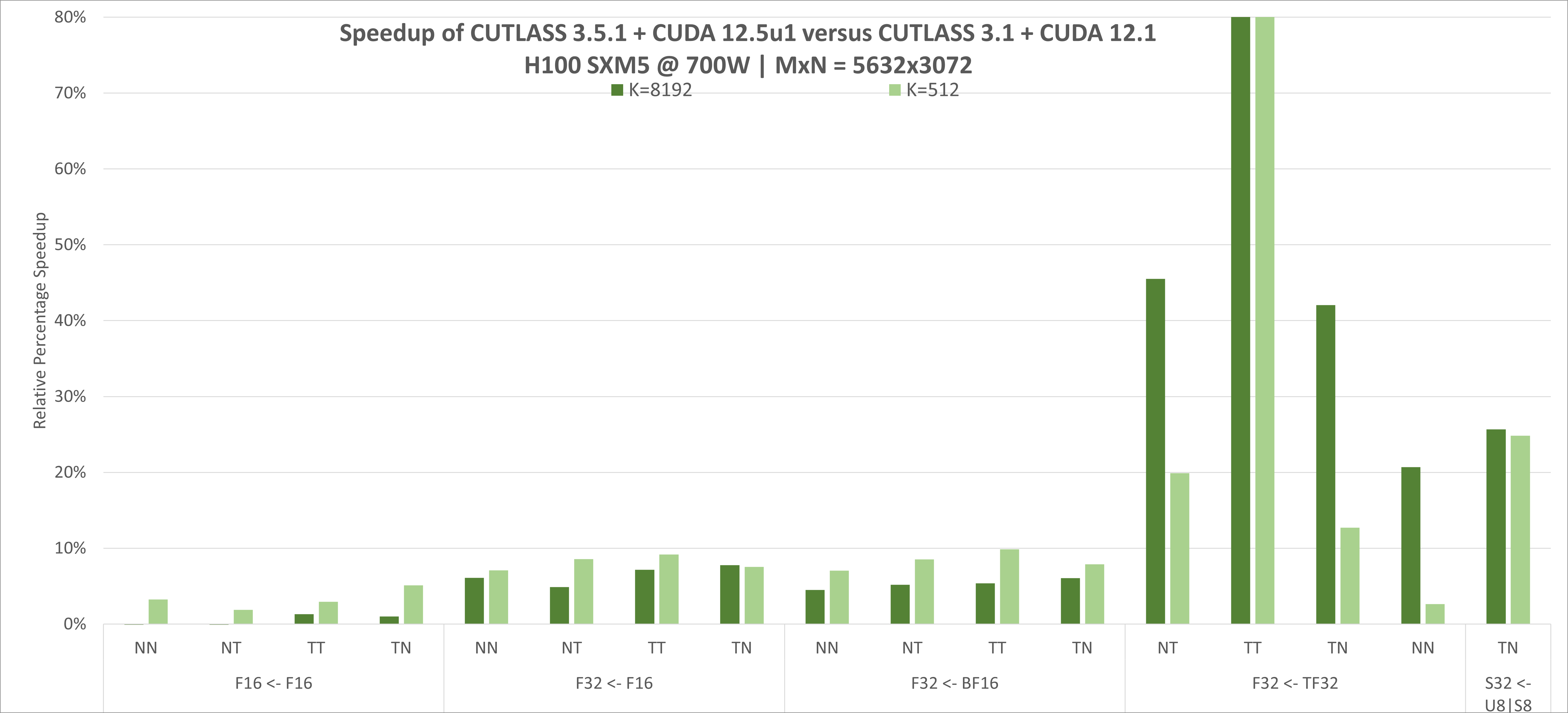
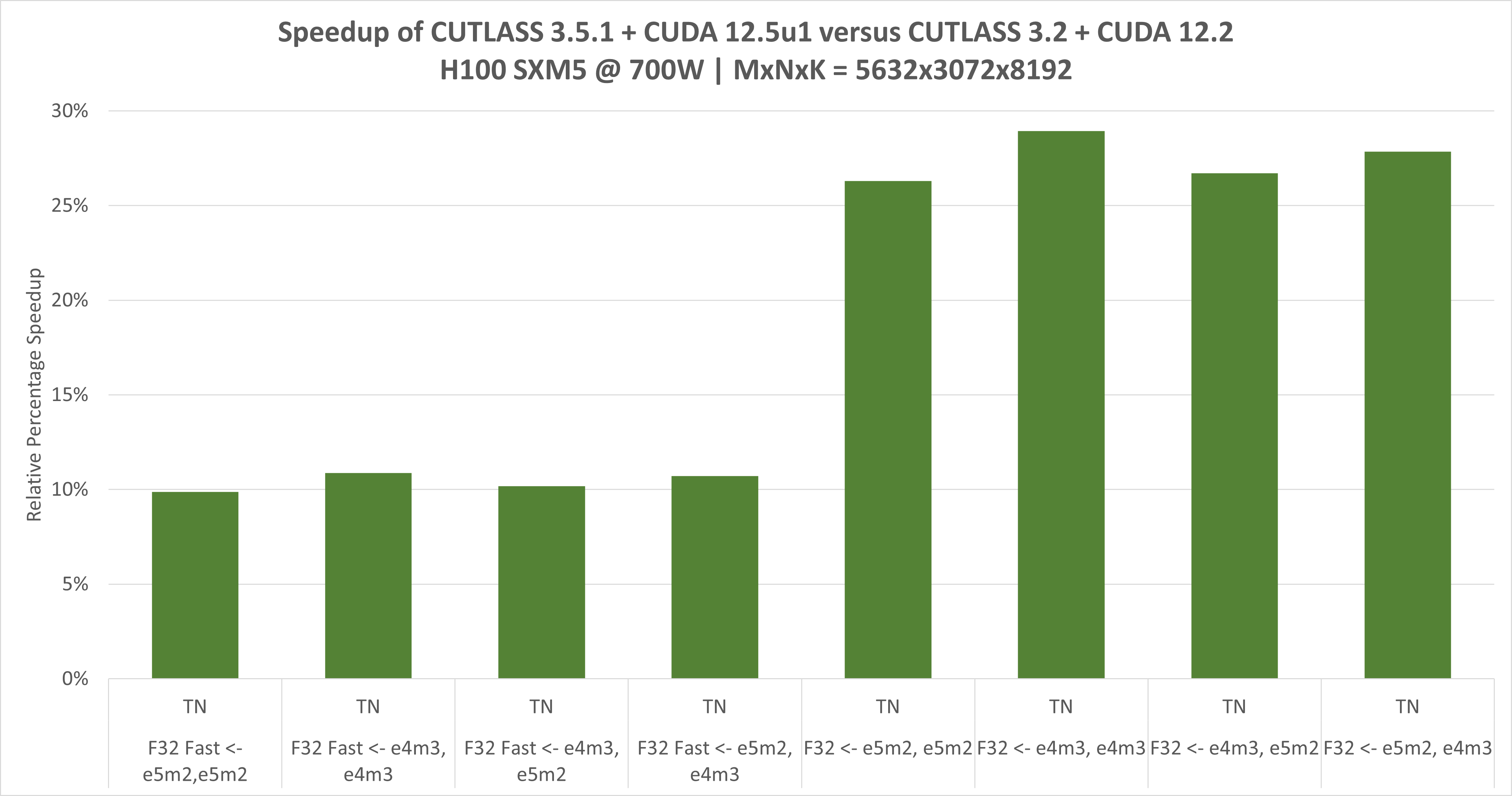
5分钟上手CUTLASS CuTe DSL
通过Python快速体验CUTLASS CuTe DSL,运行一个简单的矩阵乘法示例
🖥️ OS
⚙️ Runtime
🔧 Tools
📝 Steps
克隆项目并进入目录
获取CUTLASS最新代码
克隆仓库
$ git clone https://github.com/NVIDIA/cutlass.git进入项目目录
$ cd cutlass设置CuTe DSL环境
安装CuTe DSL Python包
进入CuTe DSL目录
$ cd python/CuTeDSL运行安装脚本(默认使用CUDA 12)
$ bash setup.sh运行简单示例
执行一个基本的矩阵乘法示例
进入示例目录
$ cd examples/python/CuTeDSL/cute运行FP16矩阵乘法示例
$ python gemm_f16_f16_f16.py✅ 验证成功
成功运行示例代码并看到正确结果
- ✓看到 'PASSED' 或 'Success' 输出
- ✓看到矩阵乘法的性能数据(GFLOPS)
- ✓没有错误信息
⚡ Quick Tips
🔍 Troubleshooting
❓ setup.sh 执行失败
→ 确保已安装正确版本的CUDA Toolkit,并设置好CUDA_HOME环境变量
❓ Python报错找不到模块
→ 确保在正确的虚拟环境中,或尝试 pip install -e . 手动安装
❓ GPU内存不足
→ 尝试减小示例中的矩阵大小,或使用更小的数据类型
❓ 编译时间过长
→ 这是正常现象,CuTe DSL需要编译CUDA内核,第一次运行后会有缓存
🎯 Next Steps
查看官方文档
访问 https://docs.nvidia.com/cutlass/latest/media/docs/pythonDSL/quickstart.html 获取详细指南
尝试更多示例
探索 examples/python/CuTeDSL/ 目录下的其他示例,如attention、convolution等
学习CUTLASS C++版本
如果你需要C++版本,查看 examples/ 目录下的C++示例
Difficulty
中级
Est. Time
2-3周
Target Audience
有一定C++和CUDA基础,希望深入理解GPU高性能计算,特别是矩阵乘法(GEMM)优化,或想使用Python DSL快速编写高性能CUDA内核的开发者、研究人员和学生。
🎯 What You'll Learn
理解CUTLASS的核心抽象概念,能够使用C++模板或Python CuTe DSL编写和优化基础的GEMM内核,并运行官方示例。
📋 Prerequisites
CUTLASS核心库是C++模板库,需要理解类、模板、STL等概念。
需要了解GPU架构、线程层次结构(Grid/Block/Thread)、内核函数、设备内存管理等基本概念。
如果想使用新的CuTe DSL(推荐新手入门路径),需要熟悉Python语法和NumPy。
理解矩阵乘法(GEMM)的基本概念。
项目主要在Linux下开发和测试,需要会使用命令行和基本的CMake编译。
📚 Resources
CUTLASS官方文档
包含C++ API文档、Python DSL文档、Quick Start Guides和详细的概念解释。
CuTe DSL Quick Start Guide
新手入门CuTe DSL最直接的实践教程。
CUTLASS C++ Quick Start Guide
学习C++模板接口的起点。
GitHub `examples/` 目录
尤其是`examples/python/CuTeDSL/`和`examples/`下编号小的C++示例,是最佳学习材料。
NVIDIA GTC 会议演讲
搜索“CUTLASS”、“CuTe”、“Tensor Core Programming”等关键词,观看最新架构上的优化实践。
GitHub Issues 和 Discussions
遇到问题时首先搜索,很多技术讨论和解决方案都在这里。
🗺️ Learning Phases
环境准备与项目概览
搭建开发环境
1. 确保系统有兼容的NVIDIA GPU(Volta架构及以上)和对应版本的CUDA Toolkit(如12.x或13.1)。 2. 克隆CUTLASS仓库:`git clone https://github.com/NVIDIA/cutlass.git`。 3. 按照README或官方Quick Start Guide,使用CMake配置和编译项目。 4. 运行一个简单的测试(如`make test_unit`中的基础测试)验证环境。
理解项目结构与目标
1. 浏览项目根目录,了解主要文件夹:`include/`(C++模板库)、`examples/`(示例代码)、`tools/`(实用工具)、`python/`(CuTe DSL)。 2. 仔细阅读README,重点关注CUTLASS 4.0引入的“CuTe DSL”部分,这是为降低学习曲线设计的Python接口。 3. 明确你的学习目标:是学习底层C++模板抽象,还是使用高级的Python DSL快速开发。
快速入门:首选CuTe DSL (Python)
跟随CuTe DSL快速入门指南
1. 进入`python/CuTeDSL`目录,按照`setup.sh`脚本设置Python环境(注意CUDA版本要求)。 2. 仔细阅读并运行`https://docs.nvidia.com/cutlass/latest/media/docs/pythonDSL/quickstart.html`中的示例。 3. 重点理解CuTe DSL的核心概念:`Layout`(布局)、`Tensor`(张量)、`Copy`(数据移动)和`MMA`(矩阵乘累加)操作。
运行并修改基础示例
1. 找到并运行`examples/python/CuTeDSL/`下的简单示例,如`simple_gemm.py`。 2. 尝试修改示例中的矩阵大小、数据类型(如从FP16改为BF16)或`Tile`形状,观察性能和结果变化。 3. 使用`cute.printf`进行调试,理解线程层次和数据映射。
学习使用Fragment-free API和TMA
1. 查看4.4.0新特性中关于“Fragment-free programming model”和“Automatic TMA descriptor generation”的示例。 2. 尝试编写一个使用`memref`直接进行`copy`和`dot`操作的小内核,体会其简洁性。 3. 理解TMA(Tensor Memory Accelerator)如何优化Hopper/Blackwell架构上的数据搬运。
深入核心:C++模板库(可选,进阶)
学习C++ Quick Start并运行基础示例
1. 阅读官方C++ Quick Start Guide。 2. 编译并运行`examples/`目录下编号较小的示例,如`00_basic_gemm`、`01_cutlass_utilities`。 3. 使用`profiler`工具(在`tools/library/scripts`中)对示例内核进行性能分析,理解不同配置(Tile大小、Stage数)的影响。
理解层次化分解
1. 研究一个简单的GEMM示例(如`00_basic_gemm`)的源代码。 2. 画出其线程块(ThreadBlock)、线程束(Warp)、线程(Thread)级别的数据划分和计算流程。 3. 理解CUTLASS中`Gemm`、`Mma`、`TileIterator`等核心模板类的作用。
探索高级特性与自定义内核
1. 尝试运行混合精度(如`10_planar_complex`)、特殊数据类型(如FP8、4-bit Integer)的示例。 2. 参考`examples/`中类似功能的内核,尝试修改模板参数(`Shape`、`Layout`、`Operator`)来定制一个满足特定需求(如特殊步长)的GEMM内核。 3. 学习使用`CuTe`(C++版本)的布局代数,这是CuTe DSL的底层基础。
实践与调试
集成与调试
1. 将你编写的CuTe DSL内核或C++内核集成到一个简单的测试框架中(如PyTorch的CUDA扩展雏形或纯C++测试)。 2. 学习使用`cuda-memcheck`和`nsight-compute`等工具进行内存错误检查和性能剖析。 3. 为你的内核编写数值正确性验证代码(与cuBLAS结果对比)。
查阅问题与社区
1. 在GitHub Issues中搜索你遇到的问题关键词,很多常见问题已有解答。 2. 如果使用CuTe DSL遇到API问题,仔细阅读对应版本的API变更说明(如README中4.4.0的API Changes部分)。
⚠️ Common Mistakes
❌ 环境配置错误(CUDA版本、编译器不兼容)
✅ 严格按照README要求配置环境。使用`nvcc --version`和`nvidia-smi`确认CUDA驱动和运行时版本匹配。优先使用项目提供的Docker环境。
❌ 混淆C++模板库和Python DSL的使用场景
✅ 明确目标:快速原型和开发用CuTe DSL;需要极致控制、研究底层算法或维护旧代码用C++模板库。新手从DSL开始。
❌ 忽略API变更导致编译或运行错误
✅ CUTLASS(尤其是DSL)更新较快。仔细阅读当前版本README中的“What‘s New”和“API Changes”部分,对应调整代码。例如,4.4.0中一些API从枚举改为了字符串字面量。
❌ Tile形状等参数设置不当导致性能低下或错误
✅ 参考官方示例中的典型配置(如128x128x32 for FP16 on Ampere)。参数需符合硬件约束(如线程块大小、共享内存容量、Tensor Core指令要求)。使用Profiler工具验证。
❌ 内存访问越界或同步错误
✅ 在CuTe DSL中善用`cute.printf`打印线程索引和地址。在C++中确保`TensorRef`的`Layout`与数据实际布局匹配。理解并正确插入`cp.async`或`TMA`操作所需的`fence`和`wait`。
🚀 Next Steps
1. **深入研究架构特性**:针对Ampere/Hopper/Blackwell的Tensor Core、TMA、异步拷贝等进行专项优化。 2. **实现复杂算子**:尝试实现卷积(Convolution)、注意力机制(Attention)等更复杂的算子,参考`examples/`中的相关实现。 3. **集成到深度学习框架**:学习如何将CUTLASS内核封装为PyTorch的CUDA扩展或JAX的定制化算子。 4. **探索AoT(Ahead-of-Time)编译**:使用CuTe DSL的AoT编译功能,生成可部署的高性能内核库。 5. **贡献代码**:从修复文档、增加示例或解决简单的GitHub Issue开始,参与开源项目贡献。