
Stable Diffusion web UI
💡 Use Cases
这是一个为需要便捷、可视化地使用 Stable Diffusion 模型进行图像生成、编辑和增强的开发者及创作者提供的一站式Web解决方案。
快速生成概念图
Problem: 设计师或内容创作者需要快速将文字创意(如“赛博朋克城市夜景”)转化为视觉图像,用于灵感参考或项目提案,但缺乏绘画技能或专业软件。
Solution: 使用项目的 txt2img 核心功能,在文本框中输入描述性提示词,选择采样方法和参数,即可在几分钟内生成多张高质量的概念图。
Example: 为游戏设计一个“森林中的魔法水晶”场景,输入提示词并调整种子和采样步数,快速生成多个视觉方案供团队讨论。
修复与增强老照片
Problem: 用户手头有模糊、低分辨率或面部破损的老照片,希望修复清晰度并自然增强细节,但传统修图软件操作复杂且效果有限。
Solution: 利用 Extras 标签页中的 GFPGAN 或 CodeFormer 进行人脸修复,并结合 RealESRGAN 等超分辨率模型提升整体画质,通过简单的网页操作即可完成。
Example: 上传一张祖父的模糊旧照,先用人脸修复工具还原面部特征,再用超分辨率模型将图片放大4倍并增强细节,获得清晰的纪念照。
为产品生成营销素材
Problem: 电商或营销人员需要为新产品(如“一款现代感咖啡杯”)制作多角度、多风格的展示图,但实拍成本高且缺乏多样性。
Solution: 结合 img2img 和图生图功能,上传产品草图或白底图,通过提示词控制风格(如“放在木质桌面上,清晨阳光,景深效果”),批量生成不同场景的营销用图。
Example: 上传一个咖啡杯的线稿,使用“极简主义风格,浅灰色背景,顶视图”等提示词,生成一套适用于网站和社交媒体的高质量产品图。
探索艺术风格与参数
Problem: AI绘画爱好者想系统研究不同采样方法、提示词权重等参数对生成结果的影响,但手动记录和对比效率低下。
Solution: 使用 X/Y/Z 绘图功能,可在一张画布上网格化对比不同参数组合(如采样器 vs. 步数)产生的图像,直观分析效果差异,并自动保存参数信息。
Example: 想确定“梵高风格,星空”的最佳参数组合,设置X轴为不同采样器,Y轴为不同CFG强度,一次性生成对比网格,快速找到理想配置。
📊 Project Info
- Language
- Python
- Stars
- ⭐ 162,893
- Forks
- 30,336
- Today
- +39
- Ranking
- #10
- Collection
- Overall
- Trending Date
- May 11, 2026
- Last Push
- 3/2/2026
🏷️ Topics
📸 Screenshots
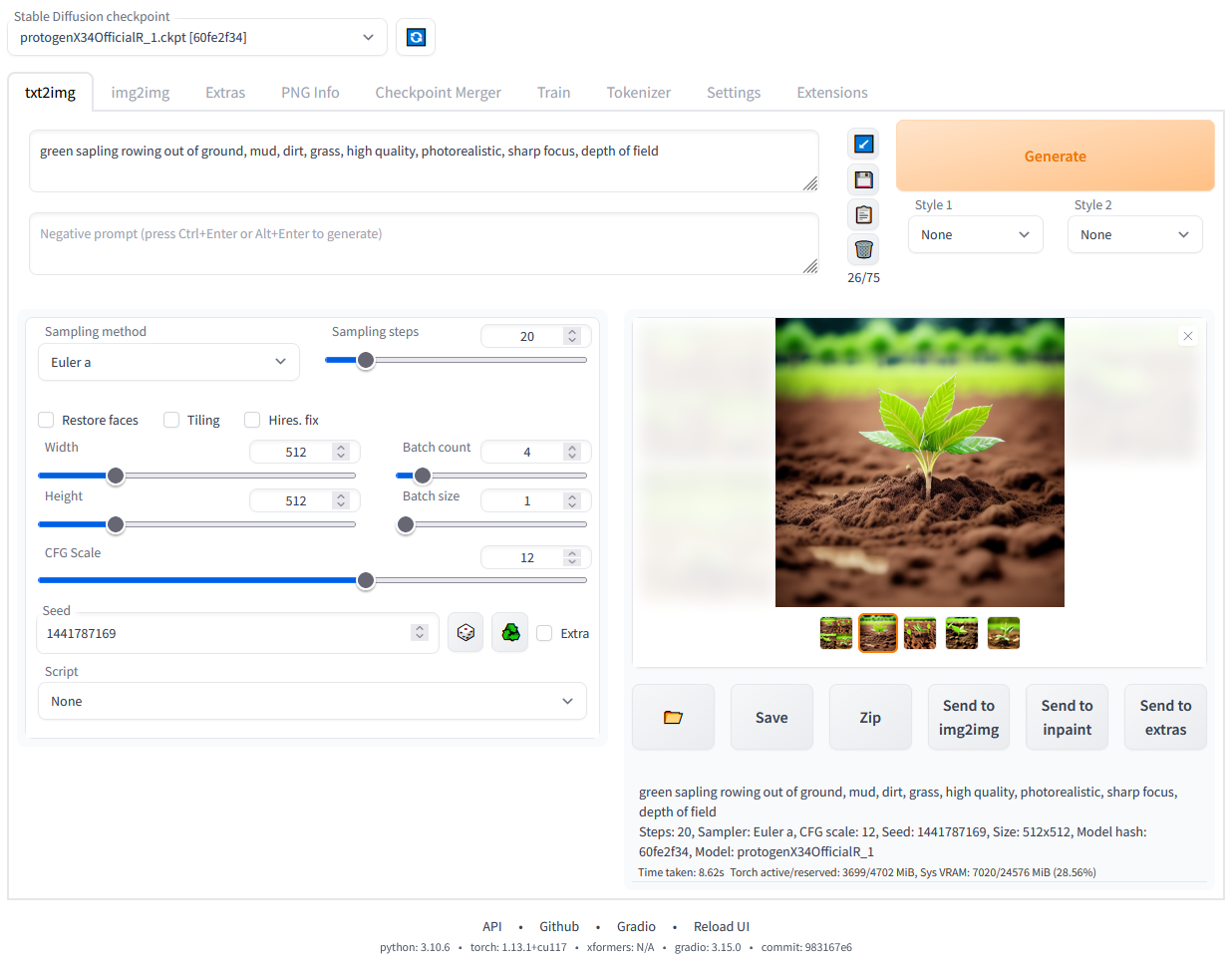
5分钟快速上手Stable Diffusion WebUI
这是一个基于Gradio的图形化界面,让你轻松使用Stable Diffusion AI图像生成模型。
🖥️ OS
⚙️ Runtime
🔧 Tools
📝 Steps
安装Python和Git
确保系统已安装Python 3.10.6和Git。Windows用户需勾选'Add Python to PATH'。
检查Python版本是否为3.10.6
$ python --version检查Git是否安装
$ git --version克隆项目仓库
打开终端或命令提示符,运行命令下载项目代码。
克隆项目到当前目录
$ git clone https://github.com/AUTOMATIC1111/stable-diffusion-webui.git运行启动脚本
进入项目目录,执行启动脚本自动安装依赖并启动WebUI。
进入项目目录
$ cd stable-diffusion-webuiWindows用户运行此批处理文件
$ webui-user.batLinux/macOS用户运行此shell脚本
$ bash webui.sh✅ 验证成功
在浏览器中打开WebUI界面,尝试生成第一张图像。
- ✓浏览器访问http://127.0.0.1:7860显示界面
- ✓在txt2img标签输入提示词如'a cat'并点击Generate生成图像
⚡ Quick Tips
🔍 Troubleshooting
❓ 启动时提示Python版本错误
→ 确保安装Python 3.10.6,并检查PATH环境变量。
❓ 下载模型失败或超时
→ 手动下载模型文件放到stable-diffusion-webui/models/Stable-diffusion/目录。
❓ 界面打开但生成图像报错
→ 检查显存是否足够,尝试降低图像分辨率或使用--medvram参数。
🎯 Next Steps
探索img2img和Inpainting功能
尝试上传图像进行编辑或局部重绘。
安装扩展插件
在Extensions标签中浏览社区插件增强功能。
调整设置优化性能
在Settings中配置xformers等加速选项。
Difficulty
初级
Est. Time
3-5小时
Target Audience
对AI绘画感兴趣的初学者,无需编程经验,但需要基本的电脑操作能力。适合想快速体验Stable Diffusion功能的AI艺术爱好者、设计师和内容创作者。
🎯 What You'll Learn
学会安装并运行Stable Diffusion WebUI,掌握文生图、图生图等核心功能,能够使用AI生成和编辑图像。
📋 Prerequisites
需要能够安装软件、解压文件、运行脚本等基本电脑操作。
如果选择手动安装方式,需要知道如何安装Python并添加到系统PATH。
如果通过Git克隆仓库,需要知道基本的Git命令或使用Git GUI工具。
确保显卡驱动已更新,以便硬件加速AI计算。
📚 Resources
项目Wiki
完整的官方文档,包含安装指南、故障排除、功能详解等
r/StableDiffusion Reddit社区
活跃的用户社区,分享作品、技巧和问题解答
YouTube教程视频
大量入门到进阶的视频教程,直观易学
Civitai
最大的Stable Diffusion模型分享平台,包含检查点、LoRA、Embeddings等
PromptHero
提示词分享平台,可以学习他人的提示词技巧
🗺️ Learning Phases
环境准备与安装
选择安装方式
根据你的操作系统和硬件选择最适合的安装方式: 1. Windows用户(NVIDIA显卡推荐):下载sd.webui.zip发布包 2. Windows用户(手动安装):安装Python 3.10.6和Git,然后克隆仓库 3. Linux用户:安装依赖后运行webui.sh 4. Mac用户:查看专门的Apple Silicon安装指南
下载与安装
按照README中的说明完成安装: - 发布包用户:下载sd.webui.zip,解压后运行update.bat和run.bat - 手动安装用户:运行`git clone https://github.com/AUTOMATIC1111/stable-diffusion-webui.git`,然后运行webui-user.bat(Windows)或webui.sh(Linux)
验证安装成功
安装完成后,浏览器会自动打开WebUI界面(通常是http://127.0.0.1:7860)。看到Gradio界面即表示安装成功。
快速入门:第一次生成图像
了解界面布局
熟悉WebUI的主要区域: 1. 顶部:模型选择、刷新按钮 2. 左侧:文生图(txt2img)、图生图(img2img)等标签页 3. 中间:提示词输入框、参数设置 4. 右侧:生成按钮、图像显示区域
第一次文生图
在txt2img标签页: 1. 在提示词(Prompt)框中输入英文描述,如"a beautiful sunset over mountains" 2. 负面提示词(Negative prompt)可以留空或输入不想要的内容 3. 点击"Generate"按钮 4. 等待生成完成,查看结果
保存你的第一张作品
生成完成后: 1. 右键点击图像可以保存 2. 图像会同时保存在项目的outputs/txt2img-images目录中 3. 图像文件包含了生成参数(PNG信息中)
核心功能探索
掌握提示词技巧
学习提示词的基本语法: 1. 使用`(word)`增加权重,`((word))`增加更多权重 2. 使用`[word]`降低权重 3. 使用`word:1.5`精确控制权重值 4. 使用`AND`连接多个概念
尝试图生图功能
切换到img2img标签页: 1. 上传一张图片 2. 输入提示词描述想要的变化 3. 调整去噪强度(Denoising strength)控制变化程度 4. 点击生成
体验局部重绘
在img2img页面选择"Inpaint"模式: 1. 上传图片 2. 使用画笔工具涂抹想要修改的区域 3. 输入提示词描述修改内容 4. 生成查看效果
使用面部修复和超分辨率
生成图像后或在图生图时: 1. 勾选面部修复选项(如GFPGAN或CodeFormer) 2. 在Extras标签页使用RealESRGAN等工具放大图像 3. 调整放大倍数和模型
进阶功能与个性化
安装和使用模型
学习如何扩展功能: 1. 从Civitai等网站下载模型(.ckpt或.safetensors文件) 2. 将模型文件放入models/Stable-diffusion目录 3. 在WebUI顶部下拉菜单刷新并选择新模型
探索扩展功能
浏览可用扩展: 1. 在Extensions标签页点击"Available" 2. 加载扩展列表 3. 安装感兴趣的扩展(如ControlNet、Dynamic Prompts等) 4. 重启WebUI应用扩展
调整常用参数
了解关键参数的作用: 1. 采样方法(Sampling method):影响图像质量和风格 2. 采样步数(Sampling steps):通常20-30步效果较好 3. 图像尺寸:必须是8的倍数 4. 种子(Seed):固定种子可以复现相同图像
⚠️ Common Mistakes
❌ Python版本错误
✅ 必须使用Python 3.10.6,不要使用更高版本。如果已安装其他版本,可以同时安装3.10.6并确保PATH指向正确版本。
❌ 显存不足错误
✅ 如果显卡显存小于4GB,在webui-user.bat中添加--lowvram参数。也可以减少图像尺寸或使用优化设置。
❌ 模型文件放错位置
✅ 检查点模型必须放在models/Stable-diffusion目录,VAE模型放在models/VAE目录,LoRA放在models/Lora目录。
❌ 提示词效果不理想
✅ 使用英文提示词效果最好,描述要具体。使用负面提示词排除不想要的内容。参考他人的成功案例学习提示词构造。
❌ 图像尺寸设置不当
✅ 图像尺寸必须是8的倍数(如512x512, 768x512)。过大的尺寸可能导致显存不足或图像扭曲。
🚀 Next Steps
掌握基础后,可以深入学习ControlNet精确控制构图、训练自己的LoRA模型定制风格、学习高级提示词工程、探索API集成到其他应用、参与社区贡献扩展功能等。