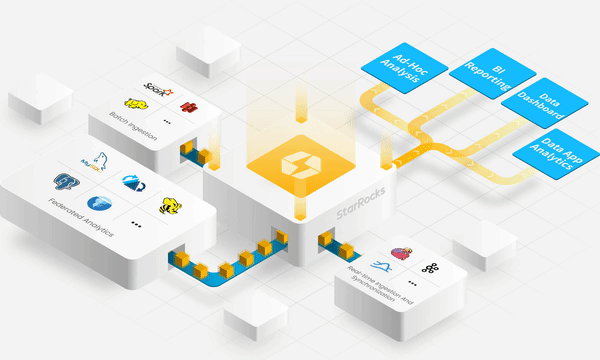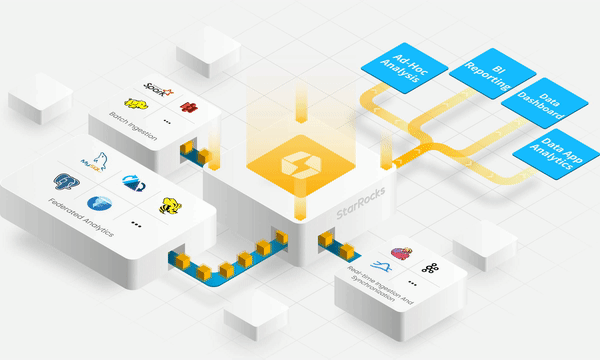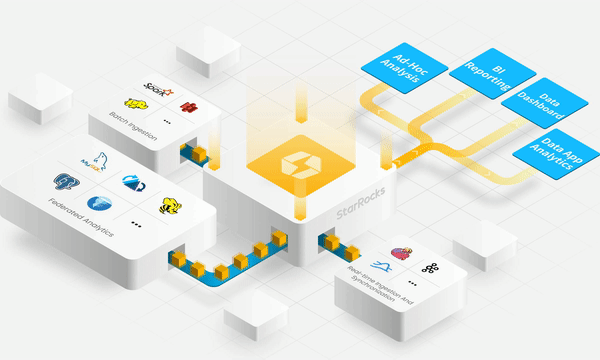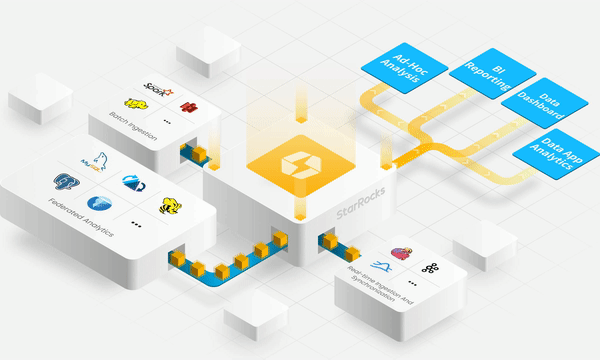
The world's fastest open query engine for sub-second analytics both on and off the data lakehouse. With the flexibility to support nearly any scenario, StarRocks provides best-in-class performance for multi-dimensional analytics, real-time analytics, and ad-hoc queries. A Linux Foundation project.
💡 Use Cases
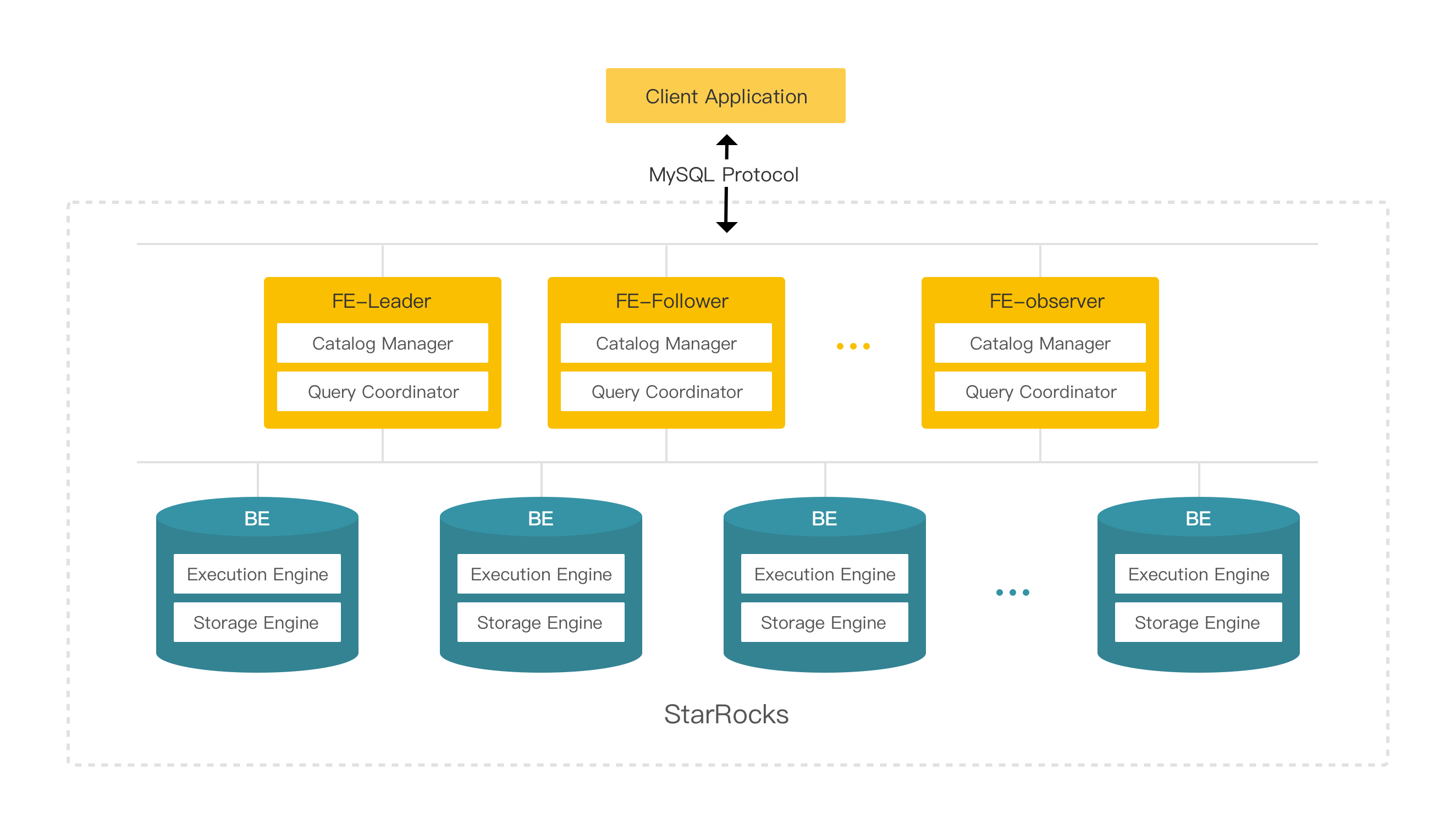
最适合需要亚秒级响应、处理海量数据实时分析与即席查询的场景。
实时数据看板
Problem: 业务需要实时监控订单、用户行为等数据,但传统数仓查询延迟高,无法满足秒级响应的需求。
Solution: 使用StarRocks的实时更新能力,直接对接Kafka等流数据源,构建实时物化视图,实现亚秒级查询响应。
Example: 电商大促期间,运营团队需要实时查看每秒的GMV、订单量、热门商品排行,StarRocks可以保证复杂多维查询在1秒内返回结果。
跨湖仓联合分析
Problem: 数据分散在数据湖(Iceberg/Hudi)和数仓中,分析时需要复杂ETL搬运数据,流程长且成本高。
Solution: 利用StarRocks直接查询数据湖外部表的功能,无需数据迁移,用统一SQL引擎对湖、仓数据进行关联分析。
Example: 分析用户画像(数仓)与日志行为数据(数据湖)的关联关系,直接编写JOIN查询,避免数据导出和整合的麻烦。
即席多维分析
Problem: 业务人员经常需要临时多维度下钻分析,但预聚合模型不灵活,复杂查询响应慢,影响决策效率。
Solution: 借助StarRocks的向量化引擎和CBO优化器,即使对原始明细表进行任意维度的即席查询,也能获得亚秒级响应。
Example: 市场部门想临时分析“不同地区、不同渠道、不同时间段的用户转化率”,无需预建Cube,直接写SQL查询,秒级出结果。
高并发报表服务
Problem: 面向大量用户的在线报表或BI工具,并发查询高时,系统容易过载,查询排队或超时。
Solution: 通过StarRocks的资源管理功能,对租户和查询进行资源隔离与限制,保障关键业务查询的稳定性和响应速度。
Example: 面向数千名销售人员的CRM系统,每人每天需频繁查询各自的业绩报表,StarRocks可确保高并发下的稳定低延迟。
📊 Project Info
- Language
- Java
- Stars
- ⭐ 11,732
- Forks
- 2,429
- Today
- +4
- Ranking
- #2
- Collection
- Language
- Trending Date
- May 29, 2026
- Last Push
- 5/29/2026
🏷️ Topics
📸 Screenshots