📑 PageIndex: Document Index for Vectorless, Reasoning-based RAG
💡 Use Cases
最适合需要从结构复杂、专业性强的长文档中,进行精准、符合逻辑的上下文检索,且希望避免向量数据库复杂性的场景。
专业长文档问答
Problem: 开发者需要从数百页的技术手册、法律合同或学术论文中精准查找特定信息,但传统向量检索经常返回语义相似但不相关的片段。
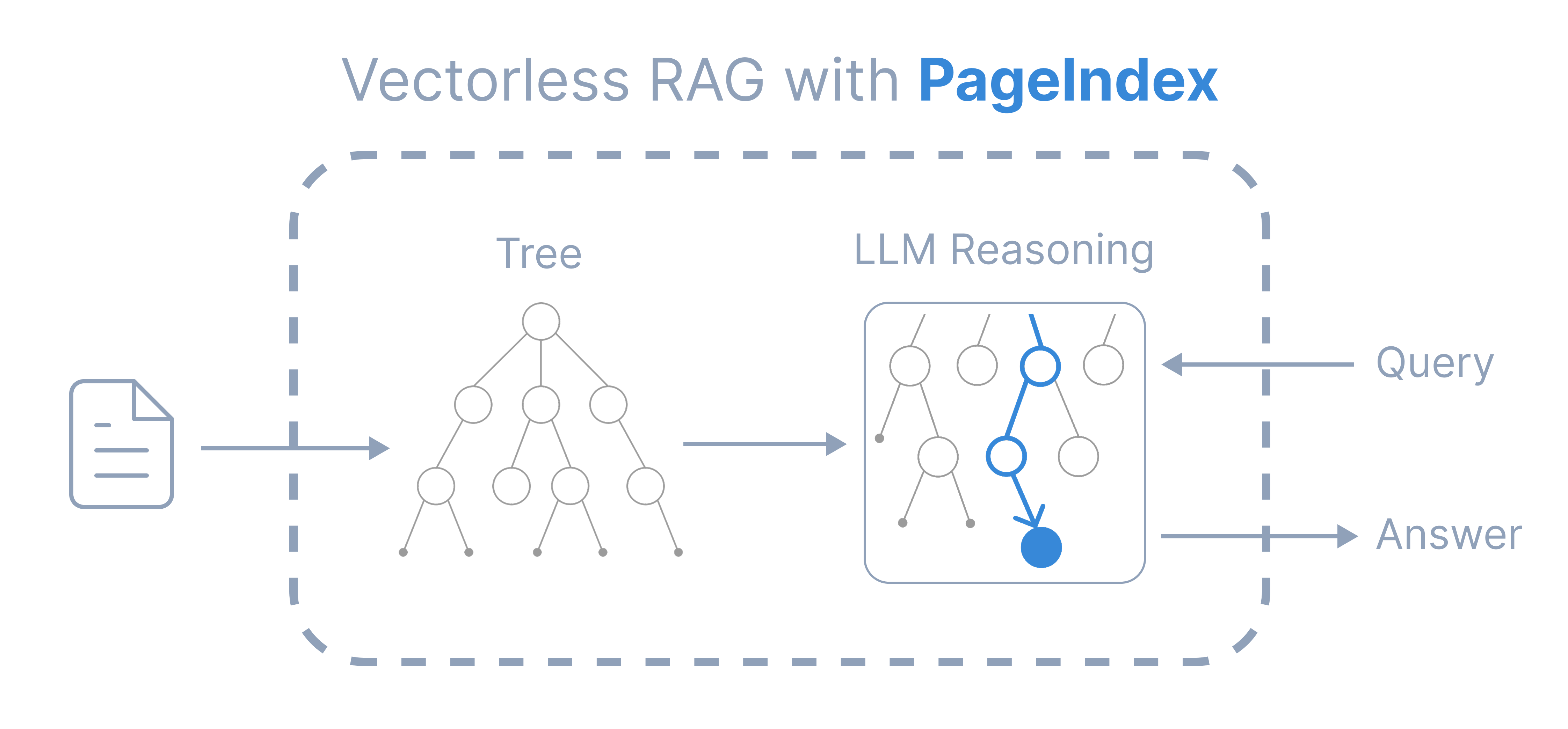
Solution: 使用PageIndex为文档构建层次化树状索引,让LLM基于推理在树中搜索,像专家一样定位到真正相关的章节,而非依赖向量相似度。
Example: 从一份300页的软件架构设计文档中,准确回答“系统在高峰期的容错机制是如何设计的?”,避免返回泛泛而谈的“系统设计”章节。
免分块文档处理
Problem: 开发者处理结构清晰的文档(如带章节的PDF)时,传统RAG的固定长度分块会破坏文档的自然逻辑结构,影响检索准确性。
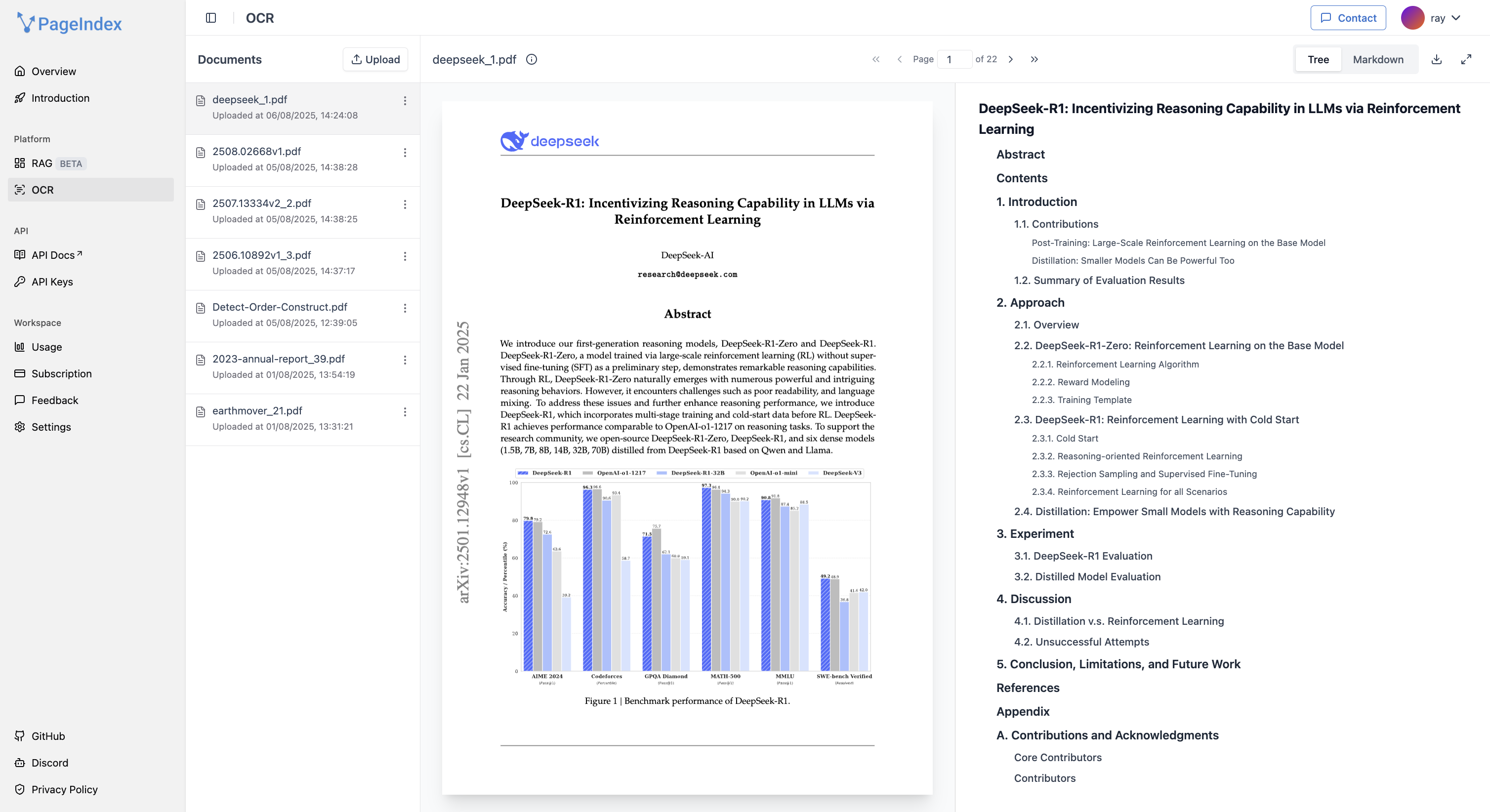
Solution: PageIndex无需分块,直接按文档的原始章节结构(如标题、子标题)构建索引,保持语义完整性,实现更符合人类阅读习惯的检索。
Example: 处理一份医学研究报告,检索“实验组在第三阶段的副作用数据”,系统能直接定位到“结果 -> 第三阶段 -> 不良反应”这一节,而不是返回一个可能截断该信息的分块。
无向量库轻量部署
Problem: 开发者希望构建一个轻量、易部署的文档问答应用,但引入和维护单独的向量数据库(如Pinecone、Weaviate)增加了复杂性和成本。
Solution: PageIndex完全无需向量数据库,仅依赖LLM的推理能力和文档的树状索引即可实现智能检索,简化了技术栈和部署流程。
Example: 在资源受限的边缘服务器或简单的云函数中,快速部署一个针对内部技术文档的问答助手,无需搭建和运维额外的数据库服务。
视觉文档直接检索
Problem: 开发者需要处理扫描版PDF或图片格式的文档,但OCR识别可能出错,且传统方法需要先OCR再向量化,流程繁琐。
Solution: 利用PageIndex的Vision-based工作流,可直接基于PDF页面图像进行推理检索,无需OCR步骤,简化了对非文本格式文档的处理。
Example: 直接上传一份扫描版的旧版产品说明书图片,询问“第5章提到的安全警告是什么?”,系统能通过视觉推理在图像索引中找到对应位置。
📊 Project Info
- Language
- Python
- Stars
- ⭐ 17,692
- Forks
- 1,259
- Today
- +378
- Ranking
- #8
- Collection
- Overall
- Trending Date
- February 25, 2026
- Last Push
- 2/10/2026
🏷️ Topics
📸 Screenshots