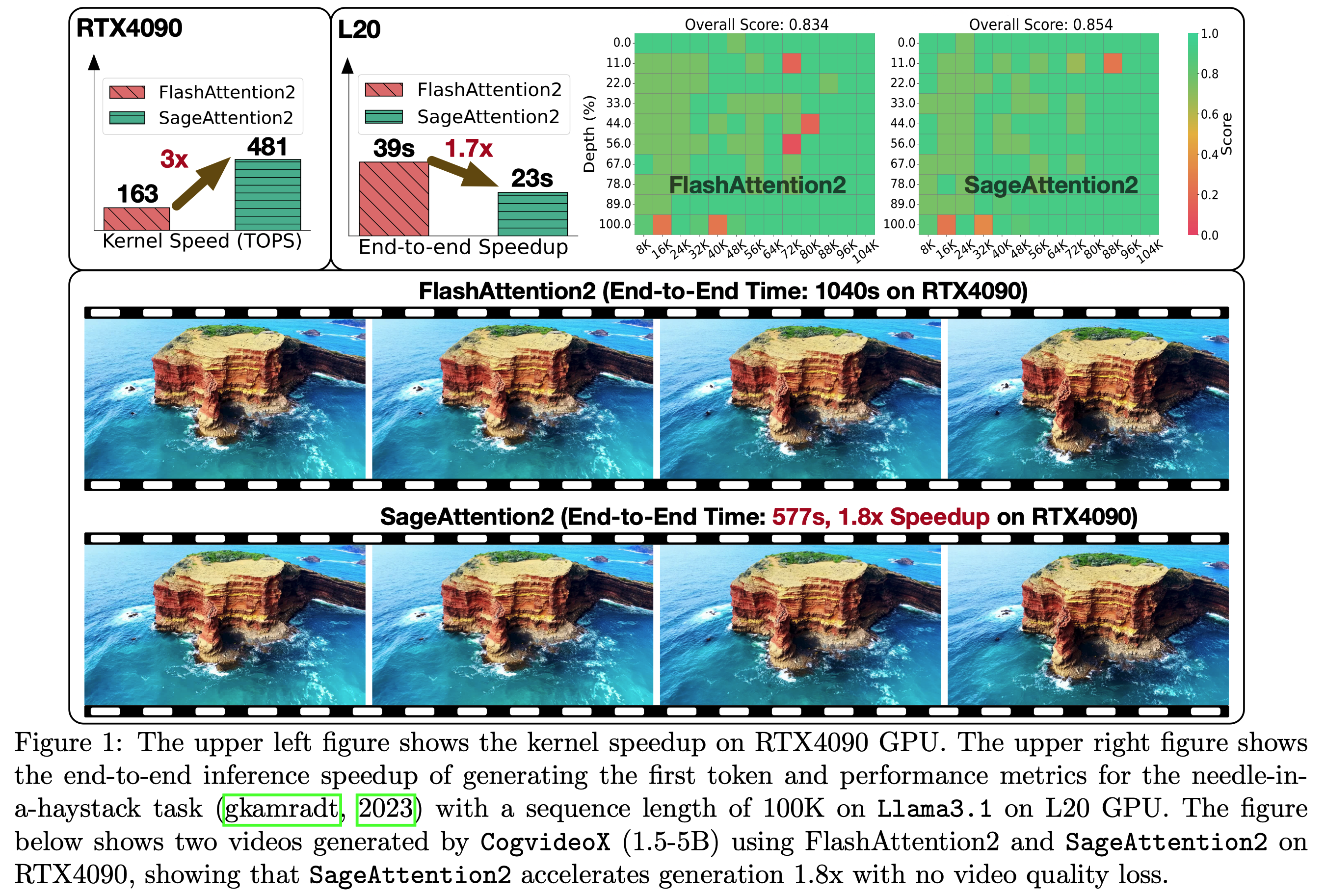
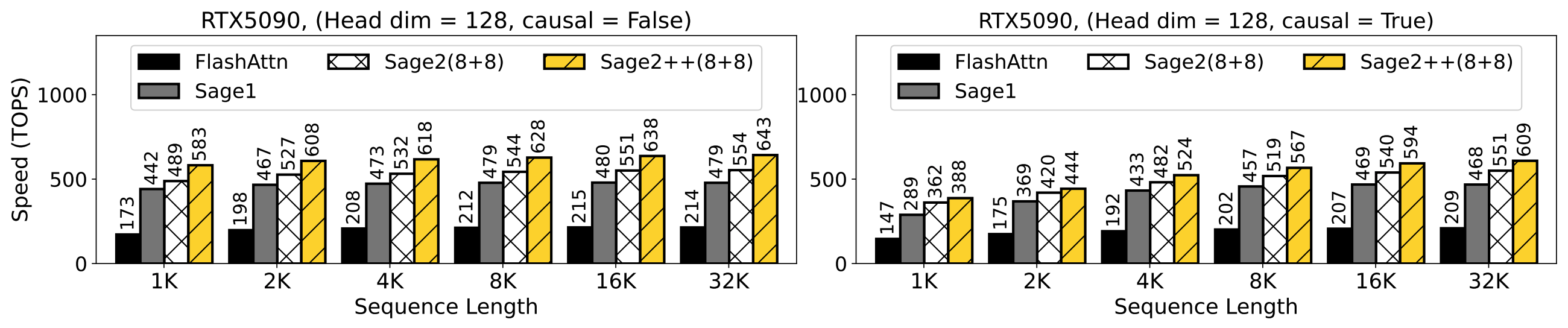
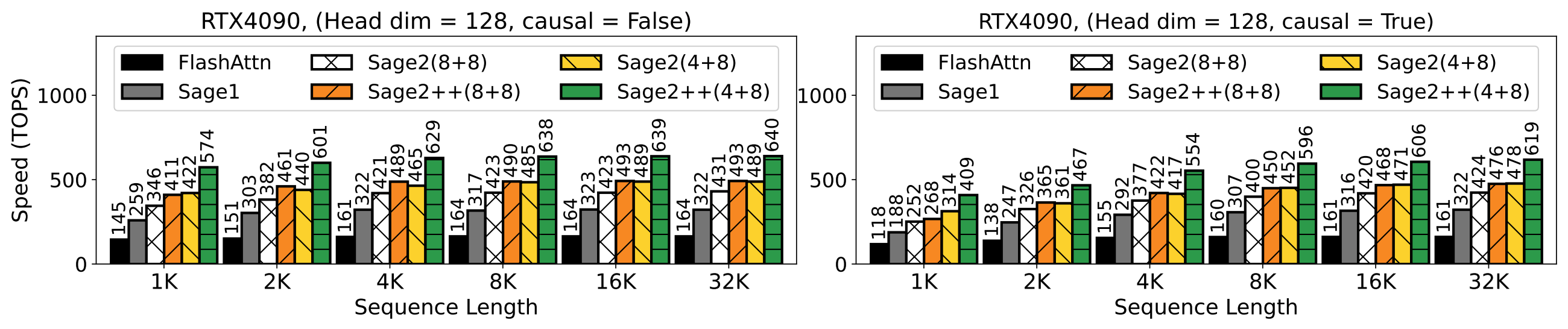
[ICLR2025, ICML2025, NeurIPS2025 Spotlight] Quantized Attention achieves speedup of 2-5x compared to FlashAttention, without losing end-to-end metrics across language, image, and video models.
📊 Project Info
- Language
- Cuda
- Stars
- ⭐ 3,407
- Forks
- 425
- Today
- +4
- Ranking
- #6
- Collection
- Language
- Trending Date
- June 3, 2026
- Last Push
- 1/17/2026
🏷️ Topics
attentioncudaefficient-attentioninference-accelerationllmllm-inframlsysquantizationtritonvideo-generatevideo-generationvit
📸 Screenshots